
如何为分布式系统设计数据库
未知
2024-03-14 12:02:59
0

面向微服务和云的数据库设计的挑战
- 在微服务架构中,数据分布在不同的节点上。其中一些节点可能位于世界各地完全不同地理区域的不同数据中心。在这种情况下,很难保证跨所有节点的数据一致性。在任何给定的时间点,不同节点之间的数据状态可能存在差异。这也被称为最终一致性问题。
- 由于数据是分布式的,因此没有像单节点整体系统那样的中央机构来管理数据。对于各个参与系统来说,使用一种机制(例如共识算法)进行数据管理是很重要的。
- 在微服务架构中,恶意行为者的攻击面更大,因为有多个活动部分。这意味着开发人员需要在构建微服务时建立一个更健壮的安全态势。
- 微服务和云计算的主要承诺是可扩展性。虽然扩展应用程序进程变得更容易,但横向扩展数据库节点就不那么容易了。如果没有适当的可扩展性,数据库可能会变成性能瓶颈。
深入研究数据管理模式
1.每个微服务的数据库
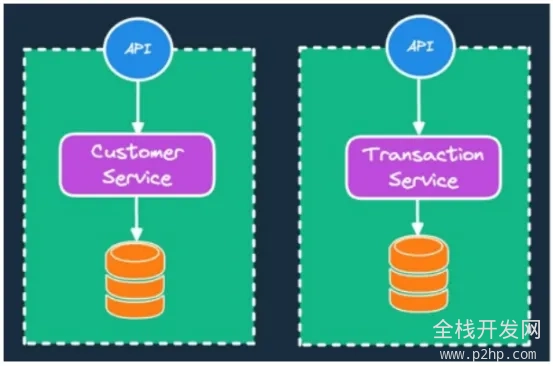 图1每个微服务数据库模式
图1每个微服务数据库模式- 为每个微服务定义有界场景。
- 管理跨多个微服务的业务事务。
2.共享数据库
- 跨团队的开发人员需要协调表的模式更改。
- 当多个服务试图访问相同的数据库资源时,可能会出现运行时冲突。
3.CQRS和事件溯源
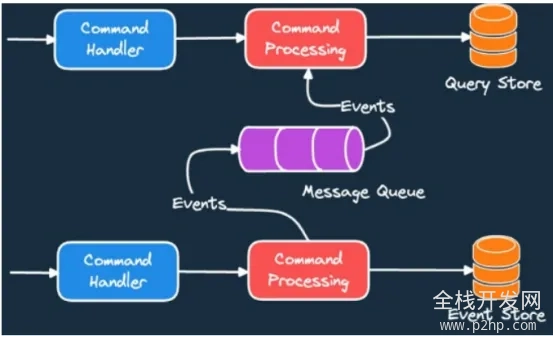 图2事件溯源和CQRS一起行动
图2事件溯源和CQRS一起行动4.Saga模式
- 基于编配的Saga
- 基于Choreography的Saga
5.分片
6.复制
- 单领导者复制
- 多领导者复制
- 无领导者复制
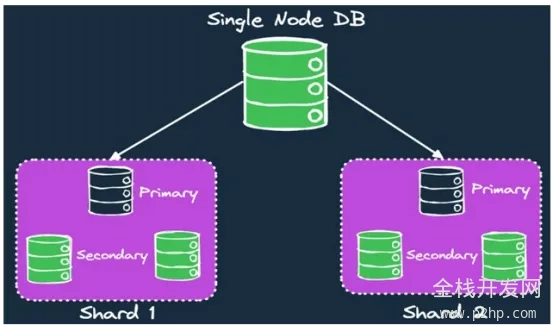 图3同时使用分片和复制
图3同时使用分片和复制云原生环境中数据库设计的最佳实践
- 必须设法设计一个具有弹性的解决方案。这是因为故障在微服务架构中是不可避免的,设计应该适应故障,并在不中断业务的情况下从中恢复。
- 当转换到其中一种模式时必须实现适当的迁移策略。可以评估的一些常见策略是模式优先与数据优先、蓝绿部署或使用扼杀模式。
- 不要忽视备份和经过良好测试的灾难恢复系统。即使对于单节点数据库,这些也很重要。然而,在分布式数据管理方法中,灾难恢复变得更加重要。
- 在微服务或云原生应用中,持续监控和可观察性同样重要。例如,分片之类的技术可能导致分区和热点不平衡。如果没有适当的监控解决方案,对这种情况的任何反应都可能来得太晚,并可能使业务面临风险。
结论
原文链接:https://www.51cto.com/article/769864.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 service@p2hp.com 进行投诉反馈,一经查实,立即处理!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 service@p2hp.com 进行投诉反馈,一经查实,立即处理!
上一篇:没有了
下一篇:分片并不意味着分布式
相关内容





如何为分布式系统设计数据库
针对微服务和云原生解决方案的数据管理已经出现了几种模式,为此需要了解在分布式环境中管理数据的重要模式...
分片并不意味着分布式
分片是一种在多个独立数据库实例之间分配数据和负载的技术。此方法通过将原始数据集拆分为分片,然后将其分...
最新文章
分片并不意味着分布式
分片是一种在多个独立数据库实例之间分配数据和负载的技术。此方法通过将原始数据集拆分为分片,然后将其分...
如何为分布式系统设计数据库
针对微服务和云原生解决方案的数据管理已经出现了几种模式,为此需要了解在分布式环境中管理数据的重要模式...