
软件开发者都必须知道的关于 Unicode 的最基本的知识
二十年前,Joel Spolsky 写道1:
没有所谓的纯文本。
不知道编码的字符串是没有意义的。你不能像鸵鸟一样再把头埋在沙子里,假装「纯」文本是 ASCII。
20 年过去了,很多事情都变了。2003 年的时候,主要的问题是:文本用的是什么编码的?
到了 2023 年,这不再是一个问题:有 98% 的概率是 UTF-8。终于!我们可以再次把头埋在沙子里了!
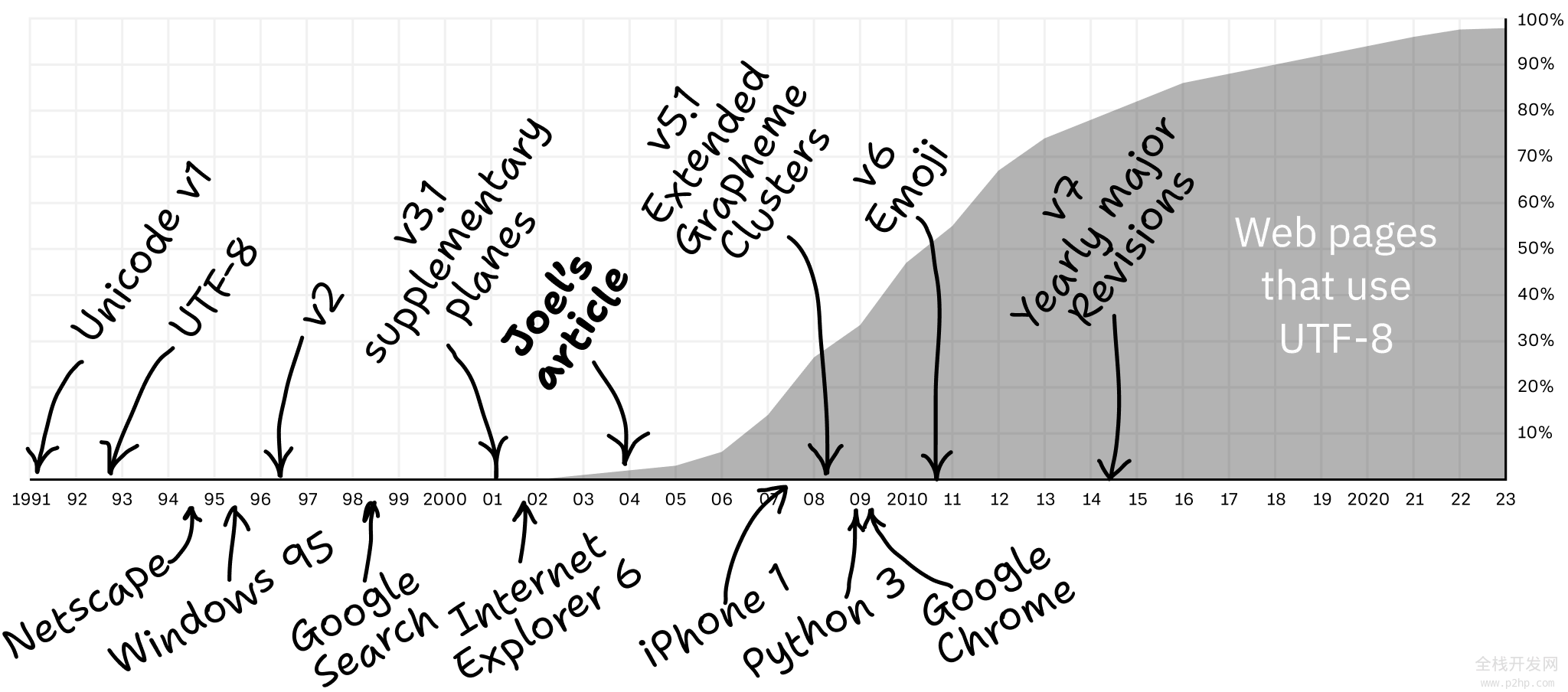
现在的问题是:我们如何正确地使用 UTF-8?让我们来看看!
什么是 Unicode?
Unicode 是一种旨在统一过去和现在的所有人类语言,使其能够在计算机上使用的标准。
在实践中,Unicode 是一个将不同字符分配给唯一编号的表格。
例如:
- 拉丁字母
A被分配了数字65。 - 阿拉伯字母 Seen
س是1587。 - 片假名字母 Tu
ツ是12484 - 音乐记号中的高音谱号(G 谱号)
𝄞是119070。 💩是128169。
Unicode 将这些数字称为码位(code points)。
由于世界上的每个人都同意哪些数字对应哪些字符,并且我们都同意使用 Unicode,我们就可以阅读彼此的文本。
Unicode == 字符 ⟷ 码位。
Unicode 有多大?
目前,已被定义的最大码位是 0x10FFFF。这给了我们大约 110 万个码位的空间。
目前已定义了大约 17 万个码位,占 15%。另外 11% 用于私有使用。其余的大约 80 万个码位目前没有分配。它们可能在未来变成字符。
这里是大致的样子:
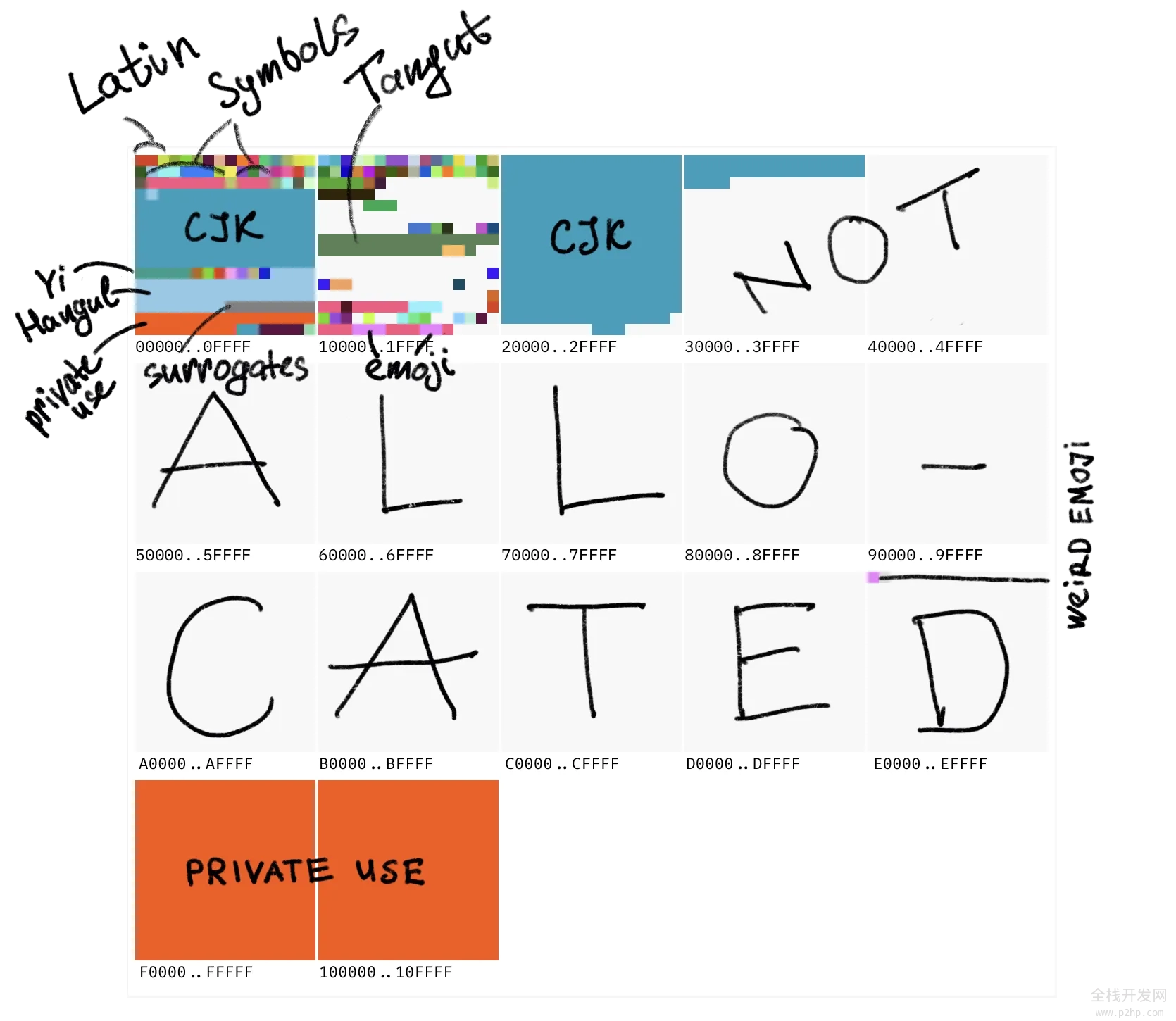
大方框 == 平面 == 65,536 个字符。小方框 == 256 个字符。整个 ASCII 是左上角小红色方块的一半。
什么是私用区?
这些码位是为应用程序开发人员保留的,Unicode 自己永远不会定义它们。
例如,Unicode 中没有苹果 logo 的位置,因此 Apple 将其放在私用区块中的 U+F8FF。在任何其他字体中,它都将呈现为缺失的字形 ,但在 macOS 附带的字体中,你就可以看到 。
私用区主要由图标字体使用:
U+1F4A9 是什么意思?
这是一种码位值写法的约定。前缀 U+ 表示 Unicode,1F4A9 是十六进制中的码位数字。
噢,U+1F4A9 具体是 💩。
那 UTF-8 是什么?
UTF-8 是一种编码。编码是我们在内存中存储码位的方式。
Unicode 最简单的编码是 UTF-32。它只是将码位存储为 32 位整数。因此,U+1F4A9 变为 00 01 F4 A9,占用四个字节。UTF-32 中的任何其他码位也将占用四个字节。由于最高定义的码位是 U+10FFFF,因此可以保证任何码位都适合。
UTF-16 和 UTF-8 不那么直接,但最终目标是相同的:将码位作为字节进行编码。
作为程序员,编码是你实际处理的内容。
UTF-8 中有多少字节?
UTF-8 是一种变长编码。码位可能被编码为一个到四个字节的序列。
这是它工作的方式:
| 码位 | 第 1 字节 | 第 2 字节 | 第 3 字节 | 第 4 字节 |
|---|---|---|---|---|
U+ | 0xxxxxxx | |||
U+ | 110xxxxx | 10xxxxxx | ||
U+ | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+ | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
将此与 Unicode 表结合起来,就可以看到英语使用 1 个字节进行编码,西里尔语、拉丁语、希伯来语和阿拉伯语需要 2 个字节,中文、日文、韩文、其他亚洲语言和 Emoji 需要 3 个或 4 个字节。
这里有几个要点:
第一,UTF-8 与 ASCII 兼容。码位 0..127,即 ASCII,使用一个字节进行编码,而且是完全相同的字节。U+0041 (A,拉丁大写字母 A) 只是 41,一个字节。
任何纯 ASCII 文本也是有效的 UTF-8 文本,任何只使用码位 0..127 的 UTF-8 文本都可以直接读取为 ASCII。
第二,UTF-8 对于基本拉丁语来说可以节省空间。这是它比 UTF-16 的主要卖点之一。对于世界各地的文本来说可能不公平,但对于 HTML 标签或 JSON 键等技术字符串来说是有意义的。
平均而言,UTF-8 往往是一个相当不错的选择,即使对于使用非英语的计算机也是如此。而对于英语而言,没有比它更好的选择了。
第三,UTF-8 自带错误检测和错误恢复的功能。第一个字节的前缀总是与第 2-4 个字节不同,因而你总是可以判断你是否正在查看完整且有效的 UTF-8 字节序列,或者是否缺少某些内容(例如,你跳到了序列的中间)。然后你就可以通过向前或向后移动,直到找到正确序列的开头来纠正它。
这带来了一些重要的结论:
- 你不能通过计数字节来确定字符串的长度。
- 你不能随机跳到字符串的中间并开始读取。
- 你不能通过在任意字节偏移处切割来获取子字符串。你可能会切掉字符的一部分。
试图这样做的人最终会遇到这个坏小子:�
� 是什么?
U+FFFD,替换字符,只是 Unicode 表中的另一个码位。当应用程序和库检测到 Unicode 错误时,它们可以使用它。
如果你切掉了码位的一半,那就没有什么其他办法,只能显示错误了。这就是使用 � 的时候。
var bytes = "Аналитика".getBytes("UTF-8");
var partial = Arrays.copyOfRange(bytes, 0, 11);
new String(partial, "UTF-8"); // => "Анал�"使用 UTF-32 不会让一切变得更容易吗?
不会。
UTF-32 对于操作码位很棒。确实,如果每个码位总是 4 个字节,那么 strlen(s) == sizeof(s) / 4,substring(0, 3) == bytes[0, 12],等等。
问题是,你想操作的并非码位。码位不是书写的单位;一个码位不总是一个字符。你应该迭代的是叫做「扩展字位簇(extended grapheme cluster)」的东西,我们在这里简称字位。
字位(grapheme,或译作字素)2是在特定书写系统的上下文中最小的可区分的书写单位。ö 是一个字位。é、각 也是。基本上,字位是用户认为是单个字符的东西。
问题是,在 Unicode 中,一些字位使用多个码位进行编码!
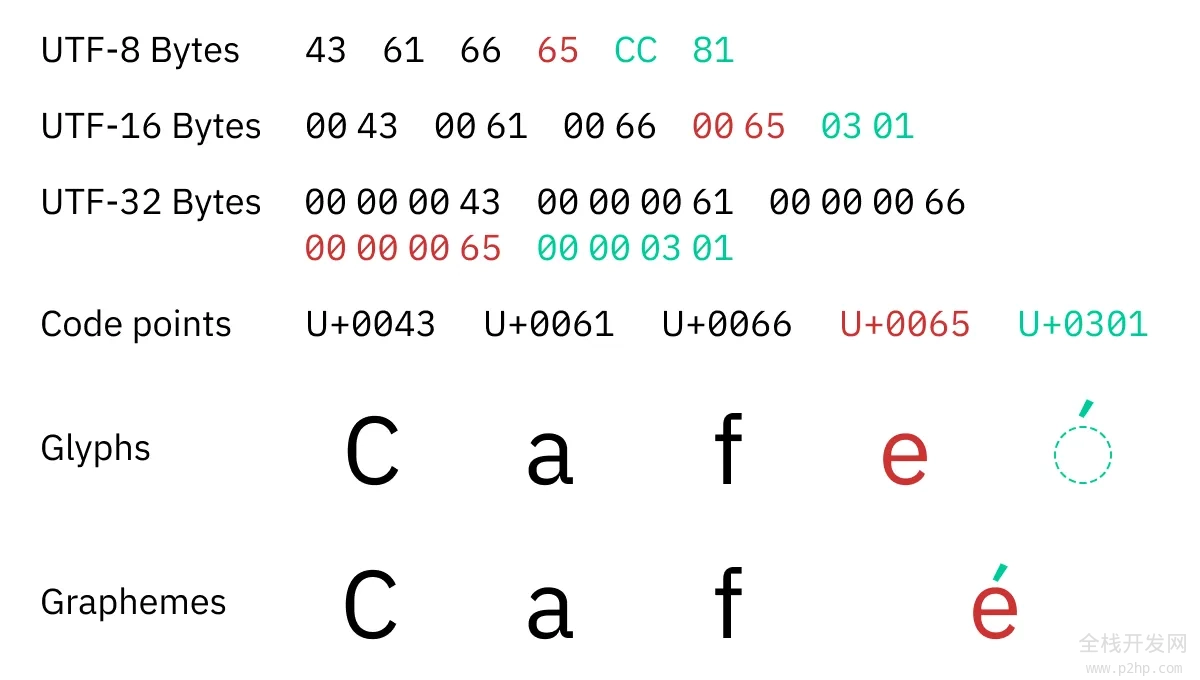
比如说,é(一个单独的字位)在 Unicode 中被编码为 e(U+0065 拉丁小写字母 E)+ ´(U+0301 连接重音符)。两个码位!
它也可以是两个以上:
☹️是U+2639+U+FE0F👨🏭是U+1F468+U+200D+U+1F3ED🚵🏻♀️是U+1F6B5+U+1F3FB+U+200D+U+2640+U+FE0Fy̖̠͍̘͇͗̏̽̎͞是U+0079+U+0316+U+0320+U+034D+U+0318+U+0347+U+0357+U+030F+U+033D+U+030E+U+035E
据我所知,没有限制。
记住,我们在这里谈论的是码位。即使在最宽的编码 UTF-32 中,👨🏭 仍然需要三个 4 字节单元来编码。它仍然需要被视为一个单独的字符。
如果这个类比有帮助的话,我们可以认为 Unicode 本身(没有任何编码)是变长的。
一个扩展字位簇是一个或多个 Unicode 码位的序列,必须被视为一个单独的、不可分割的字符。
因此,我们会遇到所有变长编码的问题,但现在是在码位级别上:你不能只取序列的一部分——它总是应该作为一个整体被选择、复制、编辑或删除。
不尊重字位簇会导致像这样的错误:

让我们先说清楚:这不是正确的行为
就扩展字位簇而言,用 UTF-32 代替 UTF-8 不会让你的生活变得更容易。而扩展字位簇才是你应该关心的。
码位 — 🥱. 字位 — 😍
Unicode 之所以难,仅仅是因为表情符号吗?
并不。没有消亡的、活跃使用的语言也使用扩展字位簇。例如:
ö(德语) 是一个单独的字符,但是多个码位(U+006F U+0308)。ą́(立陶宛语) 是U+00E1 U+0328。각(韩语) 是U+1100 U+1161 U+11A8。
所以,不,这不仅仅是关于表情符号。
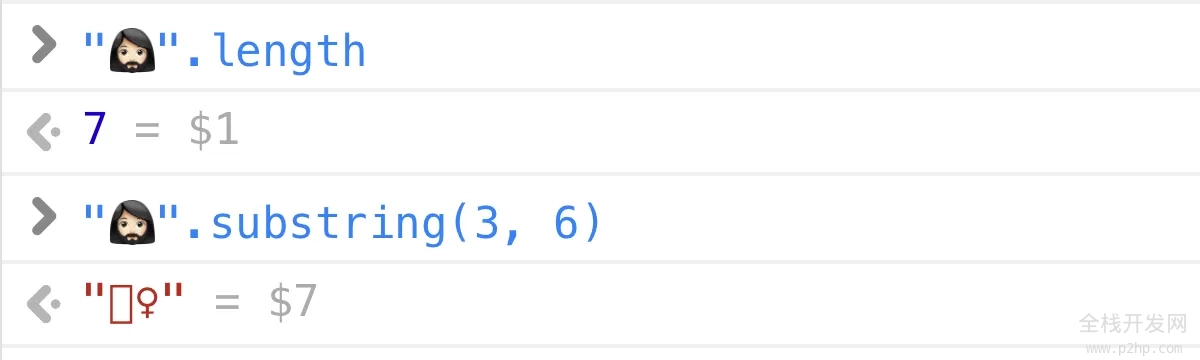
"🤦🏼♂️".length 是什么?
这个问题的灵感来自于这篇精彩的文章。
不同的编程语言很乐意给你不同的答案。
Python 3:
>>> len("🤦🏼♂️")
5JavaScript / Java / C#:
>> "🤦🏼♂️".length
7Rust:
println!("{}", "🤦🏼♂️".len());
// => 17如你所料,不同的语言使用不同的内部字符串表示(UTF-32、UTF-16、UTF-8),并以它们存储字符的任何单位报告长度(int、short、byte)。
但是!如果你问任何正常的人,一个不被计算机内部所拖累的人,他们会给你一个直接的答案:1。🤦🏼♂️ 字符串的长度是 1。
这就是扩展字位簇存在的意义:人们认为是单个字符。在这种情况下,🤦🏼♂️ 无疑是一个单独的字符。
🤦🏼♂️ 包含 5 个码位(U+1F926 U+1F3FB U+200D U+2642 U+FE0F)的事实只是实现细节。它不应该被分开,它不应该被计算为多个字符,文本光标不应该被定位在它的内部,它不应该被部分选择,等等。
实际上,这是一个文本的原子单位。在内部,它可以被编码为任何东西,但对于面向用户的 API,它应该被视为一个整体。
唯一没弄错这件事的现代语言是 Swift:
print("🤦🏼♂️".count)
// => 1基本上,有两层:
- 内部,面向计算机的一层。如何复制字符串、通过网络发送字符串、存储在磁盘上等。这就是你需要 UTF-8 这样的编码的地方。Swift 在内部使用 UTF-8,但也可以是 UTF-16 或 UTF-32。重要的是,你只使用它来整体复制字符串,而不是分析它们的内容。
- 外部,面向人类的 API 一层。UI 中的字数统计。获取前 10 个字符以生成预览。在文本中搜索。像
.count或.substring这样的方法。Swift 给你一个视图,假装字符串是一个字位簇序列。这个视图的行为就像任何人所期望的那样:它为"🤦🏼♂️".count给出 1。
我希望更多的语言尽快采用这种设计。
给读者的问题:你认为 "ẇ͓̞͒͟͡ǫ̠̠̉̏͠͡ͅr̬̺͚̍͛̔͒͢d̠͎̗̳͇͆̋̊͂͐".length 应该是什么?
如何检测扩展字位簇?
不幸的是,大多数语言都选择了简单的方法,让你通过 1-2-4 字节块迭代字符串,而不是通过字位簇。
这没有意义,也不合语义,但由于它是缺省值,程序员不会再考虑,我们看到的结果是损坏的字符串:
「我知道,我会使用一个库来做 strlen()!」——从来没有人这样想。
但这正是你应该做的!使用一个合适的 Unicode 库!是的,对于像 strlen 或 indexOf 或 substring 这样的基本功能!
例如:
- C/C++/Java: 使用 ICU。它是一个来自 Unicode 自身的库,它对文本分割的所有规则进行编码。
- C#: 使用
TextElementEnumerator,据我所知,它与 Unicode 保持最新。 - Swift: 标准库就行。Swift 默认就做得很好。
- UPD:Erlang/Elixir 似乎也做得很好。
- 对于其他语言,可能有一个 ICU 的库或绑定。
- 自己动手。Unicode 发布了机器可读的规则和表格,上面的所有库都是基于它们的。
不过无论你选哪个,都要确保它是最近的 Unicode 版本(目前是 15.1),因为字位簇的定义会随着版本的变化而变化。例如,Java 的 java.text.BreakIterator 是不行的:它是基于一个非常旧的 Unicode 版本,而且没有更新。
用个库
我觉得,整个情况都令人遗憾。Unicode 应该是每种语言的标准库。这是互联网的通用语言!它甚至不是什么新鲜玩意儿:我们已经与 Unicode 生活了 20 年了。
等下,规则一直变化?
是的!很酷吧?
(我知道,这并不)
大概从 2014 年开始,Unicode 每年都会发布一次主要修订版。这就是你获得新的 emoji 的地方——Android 和 iOS 的更新通常包括最新的 Unicode 标准。
对我们来说可悲的是定义字位簇的规则也在每年变化。今天被认为是两个或三个单独码位的序列,明天可能就成为字位簇!我们无从得知,没法准备!
更糟糕的是,你自己的应用程序的不同版本可能在不同的 Unicode 标准上运行,并给出不同的字符串长度!
但这就是我们所生活的现实——你实际上别无选择。如果你想站稳脚跟并提供良好的用户体验,就不能忽略 Unicode 或 Unicode 更新。所以,寄好安全带,拥抱更新。
每年更新
为什么 "Å" !== "Å" !== "Å"?

请将下面任何一行复制到你的 JavaScript 控制台:
"Å" === "Å";
"Å" === "Å";
"Å" === "Å";你得到了什么?False?确实是 false,并且这不是一个错误。
还记得我之前说过 ö 是两个码位,U+006F U+0308 吗?基本上,Unicode 提供了多种写法,比如 ö 或 Å。你可以:
- 从普通拉丁字母
A+ 一个连接字符组合出Å, - 或者还有一个预组合的码位
U+00C5帮你做了这件事。
他们将会看起来一样(Å vs Å),它们应该用起来一样,并且它们实际上在方方面面都被视为完全一样。唯一的区别是字节表示。
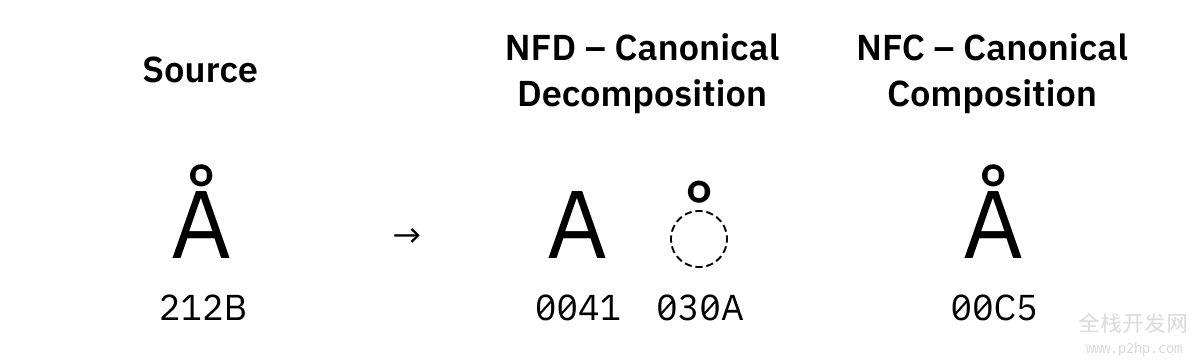
这就是我们需要归一化的原因。有四种形式:
NFD 尝试将所有东西都分解为最小的可能部分,并且如果有多个部分,则按照规范顺序对部分进行排序。
NFC,另一方面,尝试将所有东西组合成存在的预组合形式。

对于某些字符,它们在 Unicode 中也有多个版本。例如,有 U+00C5 Latin Capital Letter A with Ring Above,但也有 U+212B Angstrom Sign,它看起来是一样的。
这些也在归一化过程中被替换掉了:
NFD 和 NFC 被称为「规范归一化」。另外两种形式是「兼容归一化」:
NFKD 尝试将所有东西分解开来,并用默认的替换视觉变体。
NFKC 尝试将所有东西组合起来,同时用默认的替换视觉变体。
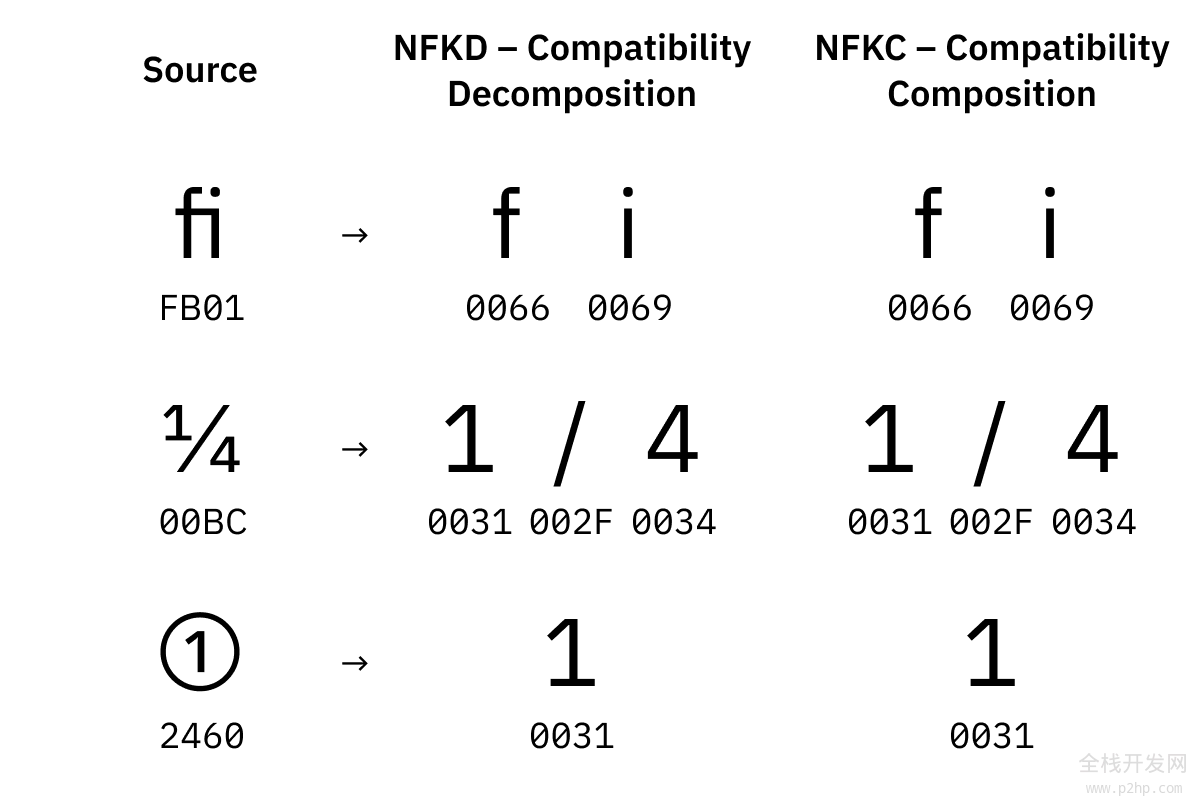
视觉变体是表示相同字符的单独的 Unicode 码位,但是应该呈现不同。比如 ① 或 ⁹ 或 𝕏。我们想要在像 "𝕏²" 这样的字符串中找到 "x" 和 "2",不是吗?

为什么连 fi 这个连字都有它自己的码位?不知道。在一百万个字符中,很多事情都可能发生。
在比较字符串或搜索子字符串之前,归一化!
Unicode 是基于区域设置的
俄语名字 Nikolay 的写法如下:

并且在 Unicode 中编码为 U+041D 0438 043A 043E 043B 0430 0439。
保加利亚语名字 Nikolay 的写法如下:

并且在 Unicode 中编码为 U+041D 0438 043A 043E 043B 0430 0439。完全一样!
等一下!计算机如何知道何时呈现保加利亚式字形,何时使用俄语字形?
简短的回答:它不知道。不幸的是,Unicode 不是一个完美的系统,它有很多缺点。其中之一就是是将相同的码位分配给应该看起来不同的字形,比如西里尔小写字母 K 和保加利亚语小写字母 K(都是 U+043A)。
据我所知,亚洲人遭受的打击更大:许多中文、日文和韩文的象形文字被分配了相同的码位:

Unicode 这么做是出于节省码位空间的动机(我猜的)。渲染信息应该在字符串之外传递,作为区域设置(locale)/语言的元数据。
不幸的是,它未能实现 Unicode 最初的目标:
[…] 不需要转义序列或控制码来指定任何语言中的任何字符。
在实际中,对区域设置的依赖带来了很多问题:
- 作为元数据,区域设置经常丢失。
- 人们不限于单一的区域设置。例如,我可以阅读和写作英语(美国)、英语(英国)、德语和俄语。我应该将我的计算机设置为哪个区域?
- 混起来后再匹配很难。比如保加利亚文中的俄语名字,反之亦然。这种情况不是时有发生吗?这是互联网,来自各种文化的人都在这里冲浪。
- 没有地方指定区域设置。即使是制作上面的两个截图也是比较复杂的,因为在大多数软件中,没有下拉菜单或文本输入来更改区域设置。
- 在需要的时候,我们只能靠猜。例如,Twitter 试图从推文本身的文本中猜测区域设置(因为它还能从哪里得到呢?)时有时会猜错3:



为什么 String::toLowerCase() 的参数中有个区域设置?
Unicode 处理土耳其语中无点 i 的方式是说明其对区域设置依赖的另一个例子。
不同于英国人,土耳其人有两种 I 变体:有点的和无点的。Unicode 决定重用 ASCII 中的 I 和 i,并只添加两个新的码位:İ 和 ı。
不幸的是,这使得 toLowerCase/toUpperCase 在相同的输入上表现不同:
var en_US = Locale.of("en", "US");
var tr = Locale.of("tr");
"I".toLowerCase(en_US); // => "i"
"I".toLowerCase(tr); // => "ı"
"i".toUpperCase(en_US); // => "I"
"i".toUpperCase(tr); // => "İ"'所以,不,你不能在不知道字符串是用什么语言编写的情况下将字符串转换为小写。
我住在美国/英国,也应该在意这件事吗?

依然应该。即使是纯英文文本也使用了许多 ASCII 中没有的「排版符号」,比如:
- 引号
“”‘’, - 撇号
’, - 连接号
–—, - 空格的变体(长空格、短空格、不换行空格),
- 点
•■☞, - 除了
$之外的货币符号(这有点告诉你是谁发明了计算机,不是吗?):€¢£, - 数学符号——加号
+和等号=是 ASCII 的一部分,但减号−和乘号×不是¯_(ツ)_/¯ , - 各种其他符号
©™¶†§。
见鬼,不用 Unicode,你甚至拼写不了 café、piñata 或 naïve。所以是的,我们同舟共济,即使是美国人。
法国人:你书的队。4
什么是代理对?
这要追溯到 Unicode v1。Unicode 的第一个版本应该是固定宽度的。准确地说,是 16 位固定宽度:

他们相信 65,536 个字符足以涵盖所有人类语言。他们几乎是对的!
当他们意识到他们需要更多的码位时,UCS-2(没有代理对的 UTF-16 的原始版本)已经在许多系统中使用了。16 位,固定宽度,只给你 65,536 个字符。你能做什么呢?
Unicode 决定将这 65,536 个字符中的一些分配给编码更高码位的字符,从而将固定宽度的 UCS-2 转换为可变宽度的 UTF-16。
代理对(surrogate pair)是用于编码单个 Unicode 码位的两个 UTF-16 单位。例如,D83D DCA9(两个 16 位单位)编码了一个码位,U+1F4A9。
代理对中的前 6 位用于掩码,剩下 2×10 个空闲位:
High Surrogate Low Surrogate D800 ++ DC00 1101 10?? ???? ???? ++ 1101 11?? ???? ????
从技术上讲,代理对的两半也可以看作是 Unicode 码位。实际上,从 U+D800 到 U+DFFF 的整个范围都被分配为「仅用于代理对」。从那里开始的码位甚至在任何其他编码中都不被认为是有效的。
UTF-16 还活着吗?
是的!
一个定长的、涵盖所有人类语言的编码的许诺是如此令人信服,以至于许多系统都迫不及待地采用了它。例如,Microsoft Windows、Objective-C、Java、JavaScript、.NET、Python 2、QT、短信,还有 CD-ROM!
自从那时以来,Python 已经进步了,CD-ROM 已经过时了,但其余的仍然停留在 UTF-16 甚至 UCS-2。因此,UTF-16 作为内存表示而存在。
在今天的实际情况下,UTF-16 的可用性与 UTF-8 大致相同。它也是变长的;计算 UTF-16 单元与计算字节或码位一样没有用,字位簇仍然很痛苦,等等。唯一的区别是内存需求。
UTF-16 的唯一缺点是其他所有东西都是 UTF-8,因此每次从网络或磁盘读取字符串时都要转换一下。
还有一个有趣的事实:Unicode 的平面数(17)是由 UTF-16 中代理对可以表达的内容决定的。
结论
让我们总结一下:
- Unicode 已经赢了。
- UTF-8 是传输和储存数据时使用最广泛的编码。
- UTF-16 仍然有时被用作内存表示。
- 字符串的两个最重要的视图是字节(分配内存/复制/编码/解码)和扩展字位簇(所有语义操作)。
- 以码位为单位来迭代字符串是错误的。它们不是书写的基本单位。一个字位可能由多个码位组成。
- 要检测字位的边界,你需要表格。
- 对于所有 Unicode 相关的东西,甚至是像
strlen、indexOf和substring这样的无聊的东西,都要使用 Unicode 库。 - Unicode 每年更新一次,规则有时会改变。
- Unicode 字符串在比较之前需要进行归一化。
- Unicode 在某些操作和渲染中依赖于区域设置。
- 即使是纯英文文本,这些都很重要。
总的来说,是的,Unicode 不完美,但
- 有一个能覆盖所有可能语言的编码、
- 全世界都同意使用它、
- 我们可以完全忘记编码和转换之类的东西
的事实是一个奇迹。把这篇文章发送给你的程序员群友们,让他们也能了解它。
的确有这样一种东西叫做纯文本,
并且它使用 UTF-8 进行编码。
感谢 Lev Walkin 和我的赞助者们阅读了本文的早期草稿。
译者注
这篇 2003 年的文章的中文翻译:每一个软件开发者都必须了解的关于 Unicode 和字符集的基本知识(没有任何借口!)。 ↩
Twitter 错误渲染俄语为保加利亚语——注意 и、й、ь、к、з 等字母的字形。 ↩
原文是法语
Touché
,意为「说得好」、「一针见血」。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 service@p2hp.com 进行投诉反馈,一经查实,立即处理!
相关内容










最新文章