
为什么 Laravel 这么优秀
Laravel 一直是我心中最优雅的后端框架,为了向更多的人解释为什么 Laravel 这么优雅?框架本身都做了什么操作?比起其他框架的优势在哪里等?我准备从一个后端最常用的 CURD 例子说起,一步一步阐述这过程中 Laravel 都是怎么完成的;以及大家(我)为什么喜欢用 Laravel。
Introduction Laravel
Laravel 的定位是一个全栈 WEB 框架,它提供了 WEB 开发的全套组件;如路由、中间件、MVC、ORM、Testing 等。这篇文章中我使用的 Demo 是最新版的 Laravel 10.x 以及 PHP 8.2。虽说从 Laravel 5.x 后 Laravel 的版本变化比较快,基本一年一个大版本,但它的核心几乎从 4.X 以来没有发生过特别大的变化。Laravel 的目录结构可能对第一次接触的人来说会很繁琐,它有十来个文件夹,但其实大部分文件夹的位置都是精心设计的,都待在应该待的位置上。

Laravel Artisan
Laravel 第一个优雅的设计就是给开发者暴露了一个 ALLINONE 的入口 ———Artisan。Artisan 是一个 SHELL 脚本,是通过命令行操作 Laravel 的唯一入口。所有和 Laravel 的交互包括操作队列,数据库迁移,生成模版文件等;你都可以通过这个脚本来完成,这也是官方推荐的最佳实践之一。如你可以通过:
php artisan serv启动本地开发环境php artisan tinkerLocal Playgroundphp artisan migrate执行数据库迁移等

和其他框架类似,Ruby on Rails 为我们提供了 rails、Django 为我们提供了 manage.py。我觉得优秀的框架都会提供一系列的 Dev Tools 帮助开发者更好的驾驭它,更优秀的框架如 Spring 除外。
接下来我们将尝试构建一个简易的课程系统,在这个系统中有教师(Teacher),学生(Student)和课程(Course),它们之间覆盖了简单的一对一、一对多、多对多等的关系,这在日常开发中也很常见。
我会按照我理解的最佳实践的做法,一步步实现一个完整的 CURD;但不会一来就把 Laravel 的各个优秀组件抛出来,而是遇到什么组件后再尝试理解它为什么要这样设计、比起其他框架的优势在哪里。这篇文章不会包含所有的代码,但你仍然可以通过这个仓库 godruoyi/laravel-best-practice 的提交记录看到我是如何一一步构建起来的。
Make Model
我们的第一步是根据 Laravel 提供的 Artisan 命令生成对应的 Model;在实际的开发中我们通常会提供额外的参数以便生成模型的时候一起生成额外的模版文件,如数据库迁移文件、测试文件、Controller 等等;我们还将用 make:model 为 Course 生成一个 CURD Controller,相关的几个 commit 我列在下面了,每个 Commit 我都尽量做到了最小:
- artisan make:model Teacher -msf
- artisan make:model Course -a –api –pest
- definition database fields of courses table & definition model relation
- definition course seeder
当模型及模型之间的关系定义完成后,在我看来整个开发任务就已经完成 50% 了。因为我们已经完成了数据表中字段的定义、表与表的关系、以及最重要的一步:如何将数据及数据之间的关系写入数据库中,下面简单的来介绍下在 Laravel 是如何完成的。
Database Migration
Laravel 的 Migration 提供了一套便捷的 API 方便我们完成绝大多数数据库及表字段的定义。Migration 的定义完整的保留了整个应用的所有迁移历史。通过这些文件我们可以在任何一个新的地方快速的重建我们的数据库设计。所有数据库的变更都通过 migration 的方式来完成也是 Laravel 推荐的最佳实践之一。
Laravel Migration 还提供了 Rollback 机制,既可以 rollback 最近的一次数据库变更。不过我不建议大家在生产环境这样做;生产环境的数据库迁移应该始终保持向前滚动,而不应该含有向后 Rollback 的操作。比如你在上一次变更操作中错误的设置了某个表的索引,那*我理解的*正确的做法不是回滚,而是创建一个新的迁移文件,并在新的迁移文件中 ALTER 之前的修改。
一个现代化的框架,应该有 Migration,下面是 Course 及中间表的定义:
Schema::create('courses', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->string('description')->nullable();
$table->unsignedBigInteger('teacher_id')->index();
$table->text('content')->nullable();
$table->timestamps();
});
// create pivot table
Schema::create('course_student', function (Blueprint $table) {
$table->unsignedBigInteger('course_id')->index();
$table->unsignedBigInteger('student_id')->index();
$table->timestamps();
$table->primary(['course_id', 'student_id']);
});
Model Relationship
Laravel 另一个强大之处在于可以通过 Eloquent 抽象「模型与模型」之间的关系;举个例子,在下面的定义中我们描述了一个 Course 可以有多个 Student、一个 Teacher;以及一个 Student 可能有多个 Course。
// Models/Course.php
public function students(): BelongsToMany
{
return $this->belongsToMany(Student::class);
}
public function teacher(): hasOne
{
return $this->hasOne(Teacher::class);
}
一旦模型间的关系定义完成,我们就可以非常方便的通过 Laravel Eloquent 查询它们之间的数据关系。Laravel 会自动帮我们处理复杂的 Join 操作,还能在一定条件下帮我们处理如 N+1 问题。来看一个例子:
$course = Course::with('teacher', 'students')->find(1)
// assert
expect($course)
->id->toBe(1)
->students->each->toBeInstanceOf(Student::class)
->teacher->toBeInstanceOf(Teacher::class);
这个例子中我们查询了 ID 为 1 的课程及它所关联的教师及学生;这将产生 3 条 SQL操作,其中还包含了一条跨中间表(course_student)的查询,而这过程中我们不需要做任何操作,Laravel 会自动根据你 model 的定义生成对应的 Join 操作。
select * from "courses" where "id" = 1
select * from "teachers" where "teachers"."id" in (5)
select
"students".*,
"course_student"."course_id" as "pivot_course_id",
"course_student"."student_id" as "pivot_student_id"
from "students"
inner join "course_student"
on "students"."id" = "course_student"."student_id"
where "course_student"."course_id" in (1)
How to save data to database
Laravel Factory 提供了一种很好的方式来 Mock 测试数据,一旦我们定义好 Model 的 Factory 规则,我们就能轻松的在开发阶段模拟出一个关系完整的数据。这比起我们手动为前端制造测试数据要方便和可靠得多,如下面的例子将为每一个课程分配一个教师和不确定数量的学生:
// database/seeders/CourseSeeder.php
$students = Student::all();
$teachers = Teacher::all();
Course::factory()->count(10)->make()->each(function ($course) use ($students, $teachers) {
$course->teacher()->associate($teachers->random());
$course->save();
$course->students()->attach($students->random(rand(0, 9)));
});
最后我们通过运行 php artisan migrate --seed,Laravel 会自动同步所有的数据库迁移文件并按照 Laravel Factory 定义的规则生成一个关系完备的测试数据。 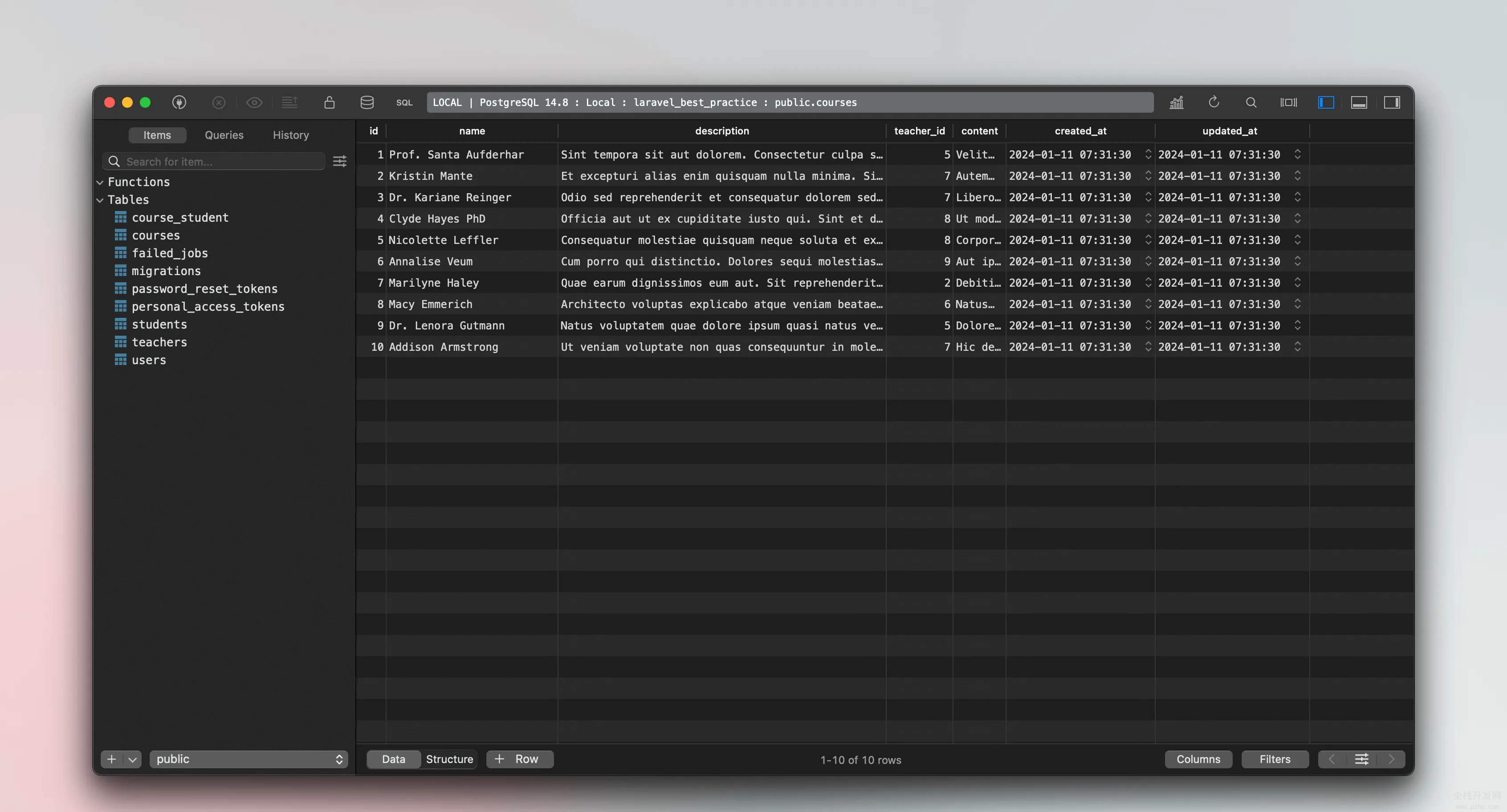
Laravel Route
在 Laravel 中我们还可以非常方便的管理应用的路由;Laravel 的路由是集中式路由,所有的路由全部写在一两个文件中;Laravel 的 Route 给开发者暴露了一套简单的 API,而通过这些 API 我们就能轻松的注册一个符合行业标准的 RSETful 风格的路由,如我们为我们课程注册的路由:
Route::apiResource('courses', CourseController::class);
Laravel 会自动帮我们注册 5 条路由如下所示,包括用于新增操作的 POST 请求,用于删除的 DELETE 请求等:
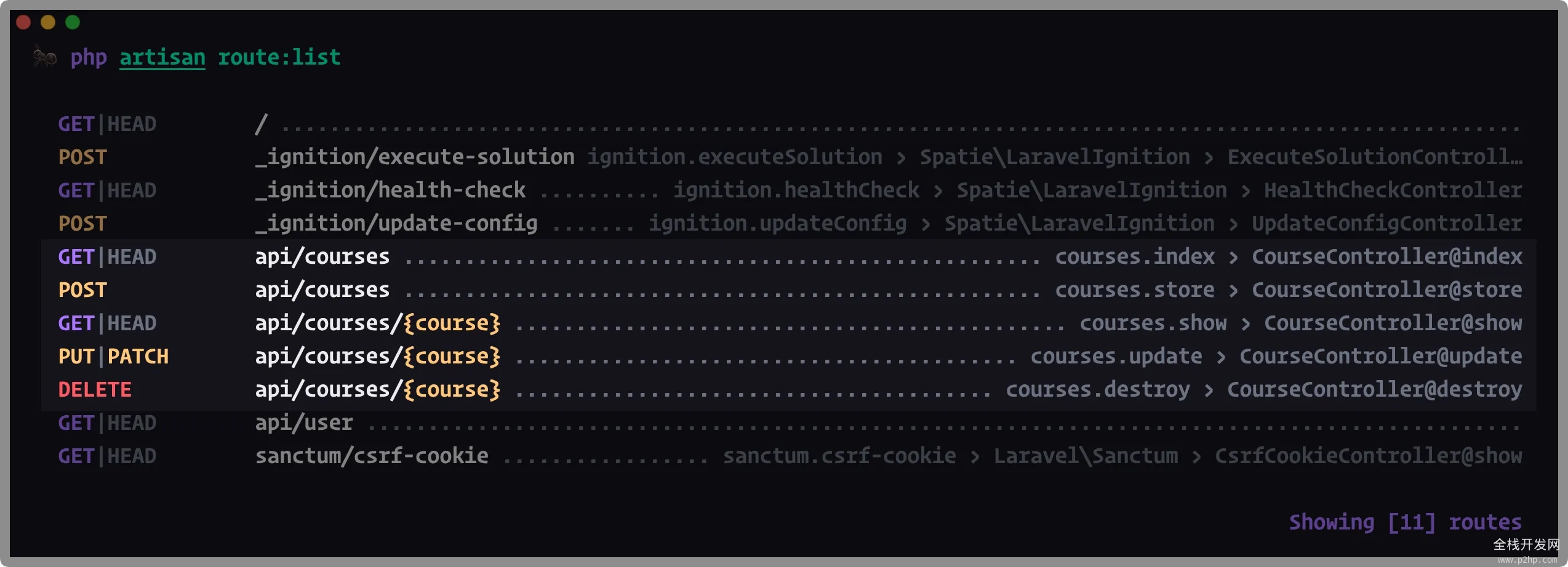
Laravel 路由虽然是非常优秀的设计,但它却不是最高效的设计。Laravel 用一个数组保存你注册过的所有路由;在进行路由匹配时,Laravel 会用你当前请求的 pathinfo 来匹配已经注册的所有路由;当你的路由数量超级多时,最坏情况下你需要 O(n) 次才能找出匹配的路由。不过这点复杂度比起注册路由&启动服务的开销几乎可以忽略不计,并且一个应用也不会有数量过多的路由,加之 Laravel 还单独提供了
artisnan route:cache命令来缓存路由的注册和匹配。我猜这也是为什么 Laravel 不需要实现其他优秀的路由算法如 Radix Tree 的原因吧。
Create Course
接下来我们来看在 Laravel 中是如何优雅的保存数据,这部分的记录你可以参考下面这几个 commit:
我们知道在进行数据操作前,都需要先对数据进行校验。而 Laravel 提供的 FormRequest 就可以非常方便的做到这一点;你可以在 FormRequest 中定义前端传入的每一个字段的验证规则。如是否必须,ID 是否应该在数据库中存在等:
class StoreCourseRequest extends FormRequest
{
public function rules(): array
{
return [
'name' => 'required|string|max:255',
'description' => 'nullable|string',
'content' => 'nullable|string',
'teacher_id' => 'required|exists:teachers,id',
'students' => 'nullable|array',
'students.*' => 'sometimes|int|exists:students,id',
];
}
}
如果你尝试传入一些无效的数据,Laravel 会直接帮我们验证并返回错误信息,如下面的 teacher_id 在数据库中并不存在。
$ echo -n '{"name": "hello", "teacher_id": 9999}' | http post http://127.0.0.1:8000/api/courses -b
{
"errors": {
"teacher_id": [
"The selected teacher id is invalid."
]
},
"message": "The selected teacher id is invalid."
}
得益于 Laravel 强大的的辅助函数和丰富的 API,在下面的代码中我们甚至可以做到一行代码就完成课程的创建及依赖关系的更新。不过这些都属于「茴」字的几种写法,在真实开发中我们应该选择适合团队并且简单易懂的。但我觉得正是这种最求极值的体验让每个用了 Laravel 的人都爱上了它。
// app/Http/Controllers/CourseController.php
public function store(StoreCourseRequest $request)
{
$course = tap(
Course::create($request->validated()),
fn ($course) => $course->students()->sync($request->students)
);
return response()->json(compact('course'), 201);
}
Storage Helper
除了上面用到的 tap 辅助函数,Laravel 另一个优秀的地方是为我们提供了超级多的辅助函数;有操作数组的 Arr,操作字符串的 Str,操作集合的 Collection,操作时间的 Carbon 等。
collect(['alice@gmail.com', 'bob@yahoo.com', 'carlos@gmail.com'])
->countBy(fn ($email) => Str::of($email)->after('@')->toString())
->all(); // ['gmail.com' => 2, 'yahoo.com' => 1]
这里还有一个有趣的现象:在 Laravel 中,辅助函数通常会放在一个名叫 Support 的文件下面的;而这在其他框架中通常会被叫做 utils。在我看来如果单比命名,support 在这里要优雅得多;并且 Laravel 的源代码中到处都充满这这种匠人式的设计;不管是函数的命名、注释、甚至是什么时候该空行,都有着自己的设计思考在里面。在 PSR2 代码规范中,还有专门的 Laravel 格式化风格。
写了这么久的代码,我不知道我写的代码到底够不够好,但好在是能嗅到一点点坏代码的味道了,而这一切都全部得益于 Laravel。
举个例子,你可以随便点开一个框架的源代码文件(如Kernel.php),看看它的命名,看看它方法的设计。我觉得这些技能在所有语言中都是通用的。
protected function sendRequestThroughRouter($request)
{
$this->app->instance('request', $request);
Facade::clearResolvedInstance('request');
$this->bootstrap();
return (new Pipeline($this->app))
->send($request)
->through($this->app->shouldSkipMiddleware() ? [] : $this->middleware)
->then($this->dispatchToRouter());
}
Testing
Laravel 为我们提供了另一个优秀的设计就是测试。它为我们提供了种类众多的测试,包括 HTTP 测试、浏览器测试(行为测试)、单元测试、数据库测试等。作为后端开发,测试应该是所有环节中最重要的一部分;我们可以不用为每个函数都编写单元测试,但对于暴露出去的每一个 API,都应该有足够的 Feature 测试来覆盖大部分可能的情况。
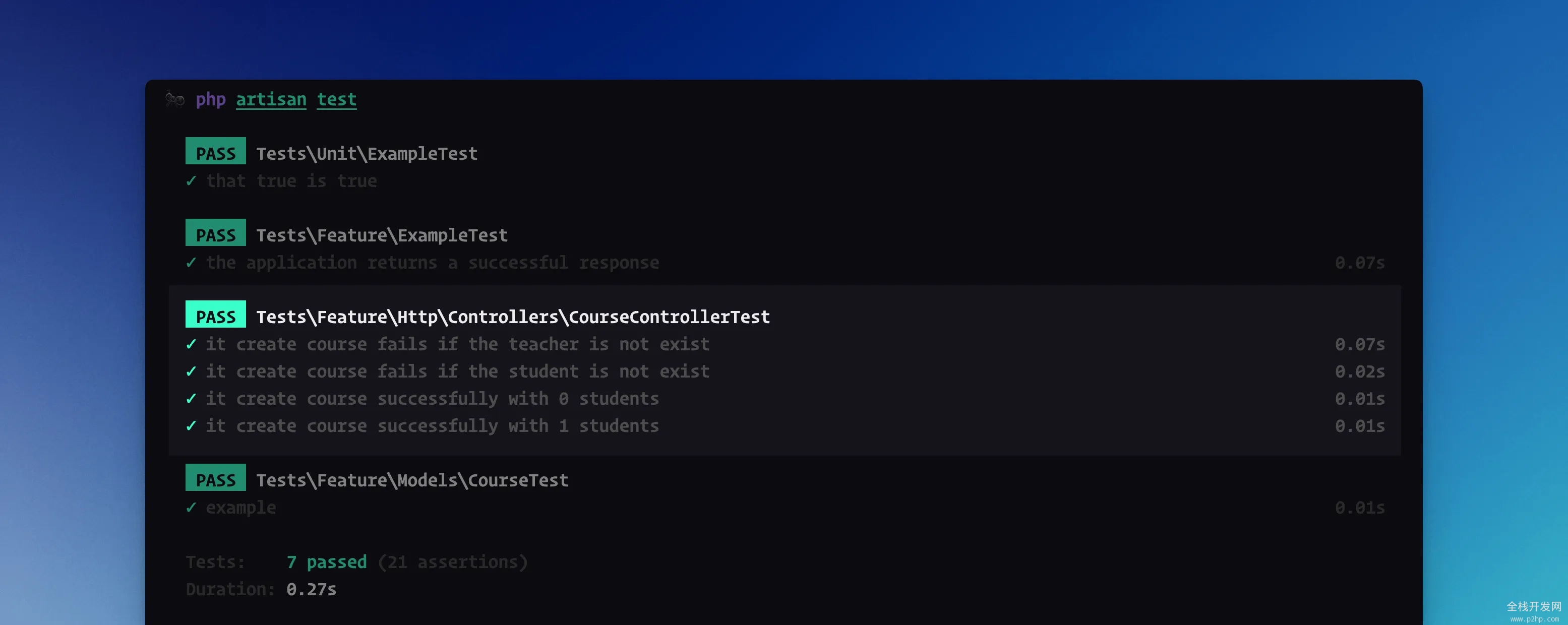
在 Laravel 中我们可以非常方便的为每一个 API 编写功能测试,如下面我们为创建课程编写的 HTTP 测试:
uses(RefreshDatabase::class);
it('create course fails if the teacher is not exist', function () {
$course = [
'name' => 'Laravel',
'description' => 'The Best Laravel Course',
'teacher_id' => 1, // teacher not exist
];
$this->postJson(route('courses.store'), $course)
->assertStatus(422)
->assertJsonValidationErrors(['teacher_id']);
});
it('create course successfully with 1 students', function () {
Teacher::factory()->create(['name' => 'Godruoyi']);
Student::factory()->create(['name' => 'Bob']);
$this->assertDatabaseCount(Teacher::class, 1);
$this->assertDatabaseCount(Student::class, 1);
$course = [
'name' => 'Laravel',
'description' => 'The Best Laravel Course',
'teacher_id' => 1,
'students' => [1],
];
$this->postJson(route('courses.store'), $course)
->assertStatus(201);
expect(Course::find(1))
->students->toHaveCount(1)
->students->first()->name->toBe('Bob')
->teacher->name->toBe('Godruoyi');
});
Update & Select & Delete
接下来我们来看如何在 Laravel 中实现查询/删除/更新操作,这部分的记录你可以参考下面这几个 Commit: - feat: create course and related testing - feat: show course and testing - feat: update course and testing - feat: delete course and testing - feat: use laravel resources
public function index(Request $request)
{
$courses = Course::when($request->name, fn ($query, $name) => $query->where('name', 'like', "%{$name}%"))
->withCount('students')
->with('teacher')
->paginate($request->per_page ?? 10);
return new CourseCollection($course);
}
public function show(Course $course)
{
return new CourseResource($course->load('teacher', 'students:id,name'));
}
在 Laravel 中可以高效的使用 Eloquent ORM 实现各种查询;如上面的例子中我们使用了 withCount 来查询课程的学生数量、用 with 加载课程对应的教师;还可以指定生成的 SQL 查询只包含某几个字段如 students:id,name。我们还使用了 Laravel Resource 来格式化最终的输出格式,这样做的原因是很多情况下我们不希望直接将数据库的字段暴露出去,你甚至还能在 Laravel Resource 中按不同的角色显示不同的字段,如下面的 secret 字段只有当用户是 admin 时才返回:
public function toArray(Request $request): array
{
return [
'id' => $this->id,
'name' => $this->name,
'email' => $this->email,
'secret' => $this->when($request->user()->isAdmin(), 'secret-value'),
'created_at' => $this->created_at,
'updated_at' => $this->updated_at,
];
}
Abstract API
Laravel 另一个优雅的地方是给开发者提供了很多优秀的组件,如 Cache、Filesystem、Queue、View、Auth、Event、Notifaction 等。这些组件都用一个共通的设计:即开发者只需要面对一套高度抽象的 API 而不用关心具体的实现。举个例子,Laravel Cache Store 的部分 API 定义如下:
interface Store
{
public function get($key);
public function put($key, $value, $seconds);
}
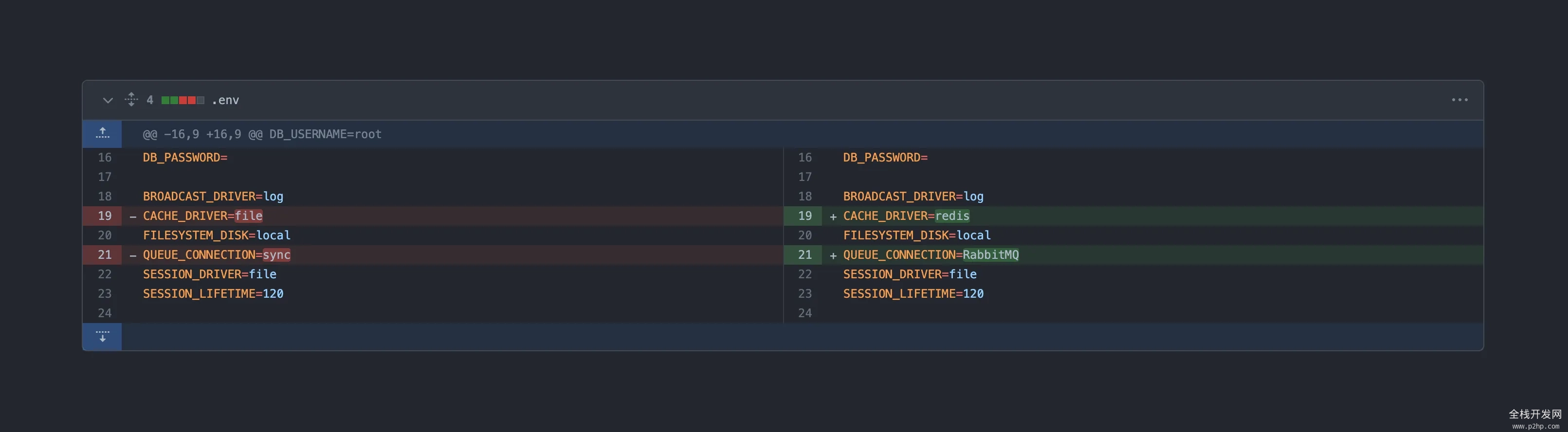
在使用 Cache 时,我们基本不用关心到底用的是文件缓存还是 Redis 缓存;在使用队列时也不用关心用的是 sync 队列还是专业的 MQ 如 Kafka。这在日常开发中十分有用,因为你不需要在本地配置各种复杂的服务。你可以在开发阶段在 .env 文件中将你的缓存驱动改为本地磁盘,将你的队列驱动改为本地同步队列;当你完成所有开发后,只需要在 staging/prod 环境修改 .env 的值就可以了,你几乎不需要做什么额外的工作。
Laravel Core - Container
Laravel Container 是整个 Laravel 框架中最核心的部分,所有的一切都是建立在它之上的。
我们知道容器只有两个功能: 1. 装东西(bind) 2. 从容器里取东西(get) 所有用到容器的框架其本质都是在框架启动的时候疯狂的往容器里装东西,容器里面的东西越多,容器提供的功能越大。如 Java 的 Spring 会在编译时为 Sprint Container 填充不同的对象,在使用时就能向容器获取不同的值。Laravel Container 也类似;Laravel 还巧妙的提供了 Service Provider 的方式来往容器里装东西,它的定义如下:
interface ServiceProvider
{
/**
* Register any application services.
*/
public function register(): void
/**
* Bootstrap any application services.
*/
public function boot(): void
}
每个 Service Provider 在注册阶段都会向 container 中设置不同的值;如 CacheServiceProvider 会向容器中注册 Cache 对象,后续在使用 Cache::get 时就使用的是这里注册的 Cache 对象,在注册阶段不应该向容器中获取值,因为此时服务可能还没有 Ready;启动阶段一般用来控制如何启动你的服务,如你可以在这个阶段中 Connect to Server、Start engin 等等。Laravel 默认会注册 20 多个 Service Provider,每个 Service Provider 都为 Laravel 提供了一种新的能力:如 Cookie/Session/DB/Filesystem 等。它的所有的核心组件都是通过这种方式注册的,正是因为如此众多的 Service Provider 才使得 Laravel Container 更加强大。
我最喜欢 Laravel Container 的一点是它支持获取任何对象,即使容器里没有,它也能给你造一个。Laravel Container 支持自动帮你构造容器中不存在的对象,如果这构造这个对象时还依赖另外的对象,Laravel 会尝试递归的创建它,举个例子:
class A
{
public function __construct(public B $b) {}
}
class B
{
public function __construct(public C $c) {}
}
class C
{
public function __construct(public string $name = 'Hello C')
}
$a = (new Container())->get(A::class);
expect($a)
->not->toBeNull()
->b->not->toBeNull()
->b->c->not->toBeNull()
->b->c->name->toBe('Hello C');
正是因为这个特性,所以在 Laravel 的绝大多数方法参数中,你可以随意的注入任意数量的参数;这也是我最喜欢的一点。Laravel 会自动帮我们从容器中获取它,如果容器不存在,则会尝试初始化它。如我们上面的 CURD 的例子中,Request 对象就是 Laravel 自动注入的,你还可以在后面注入任意数量的参数:
class CourseController extends Controller
{
public function index(Request $request, A $a, /* arg1, arg2, ... */)
{
// ...
}
}
Laravel Pipeline #
Laravel 另一个优秀的设计是 Pipeline ;Laravel 的 Pipeline 贯穿了整个框架的生命周期,可以说整个框架都是在一个流水线的管道里启动起来的。而 Laravel Pipeline 的实现也很有趣;我们知道在常见的 Pipeline 设计中,大多会通过 for 循环来实现,而 Laravel 则采用的是最简单却又最复杂的实现 array_reduce。
我们知道 array_reduce 可以将一组数据串起来执行,如:
array_reduce([1, 2, 3], fn($carry, $item) => $carry + $item) // 6
但当 array_reduce 遇到全是闭包的调用时,情况就复杂了:
$pipelines = array_reduce([Middleware1, Middleware2, /* ... */], function ($stack, $pipe) {
return return function ($passable) use ($stack, $pipe) {
try {
if (is_callable($pipe)) {
return $pipe($passable, $stack);
} elseif (! is_object($pipe)) {
[$name, $parameters] = $this->parsePipeString($pipe);
$pipe = $this->getContainer()->make($name);
$parameters = array_merge([$passable, $stack], $parameters);
} else {
$parameters = [$passable, $stack];
}
return $pipe(...$parameters);
} catch (Throwable $e) {
return $this->handleException($passable, $e);
}
})
}, function ($passable) {
return $this->router->dispatch($passable);
})
// send request through middlewares and then get response
$response = $pipelines($request);
上面的代码其实是 Laravel 中间件的核心代码,也是 Laravel 启动流程的核心实现;虽然加入了各种样的闭包后导致函数阅读起来十分痛苦,但它的本质其实很简单;就是像洋葱一样将所有的中间件包起来,然后让请求从最外层一层一层的穿过它,每一层都可以决定是否继续向下执行,而最后的心脏部分是最终要执行的操作。举个简单的例子,我们可以将一段文本通过各种过滤后再保存进数据库,如:
(new Pipeline::class)
->send('This is the HTML content of a blog post
')
->through([
ModerateContent::class,
RemoveScriptTags::class,
MinifyHtml::class,
])
->then(function (string $content) {
return Post::create([
'content' => $content,
...
]);
});
Laravel Comnication
Laravel 的强大离不开社区的支持,这十年来 Laravel 官方已经发布了 20 多种周边生态,这里摘抄一个来自@白宦成关于 Laravel 和其他框架的对比图。
| 项目 | Laravel | Rails | Django |
|---|---|---|---|
| ORM | 有 | 有 | 有 |
| 数据库迁移 | 有 | 有 | 有 |
| 发送邮件 | Mailables | ActionMailer | SendMail |
| 接收邮件 | 无 | Action Mailbox | 无 |
| 管理框架 | Nova | 无 | Django Admin |
| 单页管理 | Folio | 无 | flatpages |
| 系统检查框架 | Pluse | 无 | checks |
| Sitemap | 无 | 无 | Sitemap |
| RSS & Atom | 无 | 无 | Feed |
| 多站点框架 | 无 | 无 | Sites |
| 前端处理 | Asset Bundling | Asset Pipeline | 无 |
| WebSocket | Broadcasting | Action Cable | Django Channels |
| 队列 | Queues | Active Job | 无 |
| 文本编辑器 | 无 | Action Text | 无 |
| GIS | 无 | 无 | DjangoGIS |
| 信号调度框架 | 无 | 无 | Signals |
| 支付框架 | Cashier | 无 | 无 |
| 浏览器测试 | Dusk | 无 | System Testing |
| 自动化部署工具 | Envoy | 无 | 无 |
| Redis 调度 | Horizon | 无 | 无 |
| 完整用户系统 | Jetstream | 无 | 无 |
| Feature Flag | Pennant | 无 | 无 |
| Code Style Fixer | Pint | 无 | 无 |
| 搜索框架 | Scout | 无 | 无 |
| OAuth | Socialite | 无 | 无 |
| 系统分析 | Telescope | 无 | 无 |
除了官方,社区本身已有非常多的第三方扩展;有快速生成 Admin 管理后台的各种 Generater、有操作 Excel 的 SpartnerNL/Laravel-Excel、有高效操作图片的 Intervention/image、还有最近要被纳入默认测试框架的 Pest 以及在屎一样的 API 之上构建出来的最好用的微信 SDK EasyWechat。你几乎能在 PHP 生态中找到任何你想找的轮子。
说到这儿,不得不说 PHP 生态中了一个强大的存在 Symfony。Symfony 完全是另一个可以和 Laravel 媲美的框架,甚至在很多设计上比 Laravel 还要超前;并且 Laravel 的核心组件如路由/Request/Container 都是构建在 Symfony 之上的。但 Symfony 的推广没有 Laravel 那么好运,Symfony 发布到现在已经 12 年了,仍然处于不温不火的地位(国内看的话),我想大概是没有一个像 Taylor Otwell 一样即会写代码还会营销的 KOL 吧。
正是因为这些强大的社区支持帮助 Laravel 变得更加强大,也正是因为这些繁荣的生态保护着 PHP 一步一步走到现在。有些开发者可能觉得 PHP 已经走向衰亡了,并且十分鄙视 PHP 着门语言。我其实很不明白作为一名工程师为什么我们会瞧不上某一门语言?每一门语言都有着自己天然的优势,PHP 作为一门脚本语言在 WEB 开发这块儿有着极快的开发速度,加上上手难度低,工资不高,对于初创型企业来何尝不为一个好的选择呢。我不会因为写 Python 就觉得 PHP 屁都不如,也不因为写 Rust 就觉得 Go 狗都不如;在我看来,语言只是实现产品的一种方式,不同的语言在不同的领域有自己的优势,我们应该学习不止一门语言,并尽量了解每一门语言的优缺点,在完成开发时选择自己以及团队合适的,而不是只会写 Java 就觉得其他语言啥都不是。
不足
Laravel 为人垢弊的问题就是太慢了,一个普通的应用一个 RTT 可能也要 100~200 ms;当遇到稍微大一点的并发请求时,CPU 的负载就奔着 90% 去了。为了解决 Laravel 速度太慢这一问题,Laravel 团队在 2021 年的时候推出了 Laravel/Octane,如果你对 Laravel Octane 感兴趣,也可以看看我之前写的文章 — Laravel Octane 初体验。加持了 Laravel Octane 的应用,我们可以把请求响应做到 20ms 以内。
不过我觉得 Laravel 的不足不在性能,毕竟 PHP 作为脚本语言,就算我们把它优化到极致,也不可能达到类似 Go 那么高的吞吐率,如果真的是为了性能,那为什么不选择其他更适合的语言呢?
在我看来最大的不足是繁重的社区生态;Laravel 之前只有 Blade 模版引擎,其语法和其他模版引擎大同小异,学起来很容易上手;后来 Laravel 推出了 Livewire 和 Inertiajs。Livewire 和 Inertiajs 都是一种类前端框架,它们提供了一种更加高效的方式来管理前端页面,并且能更好的和 Laravel 整合在一起。但是它却带来了更高的学习成本和更多人力资源的浪费。本来我们只需要熟悉标准的 Vue/React API 就好了,现在却不得不学习一种新的语法,而这些语法是构建在我们熟悉的 API 之上的;有时候你原始的 API 你知道怎么写,但是新框架的新语法让你不得不查看更多的文档甚至源码,你不得不花更多的时间去适配它;而当你的团队有新人接手这些项目时,他也得跟你走一样的路,并且 Laravel 团队说不定哪天还会弃用它们(如 Laravel-Mix)。
这里还有个例子是 Laravel 在之前推出了 Laravel Bootcamp 用来教新人怎么快速上手 Laravel,但这之前只推出了两个版本,即 Livewire 和 Inertia,好在是被社区大佬及时反应后才在再后来加上了最原始的 Blade 支持。
Laravel 官方还推出了 Laravel Sail、Laravel Herd 还有更早之前推出现在被弃用的 Laravel Homestead 等本地开发环境工具;而部署工具 Laravel 推出了 Laravel Forge、Laravel Vapor 还有 Laravel Envoyer;如果你作为一个 Laravel 新人你知道用什么搭建本地开发环境吗?又用什么部署你的 Laravel 应用吗?说实话我用了 Laravel 这么久我也不知道。我更建议大家的是如果你对 Laravel 感兴趣,不要一来就接触 Laravel 这些复杂的概念,老老实实的在本地安装好 PHP/Nginx/PostgreSQL 或者 Docker;而如果你要还要用它写前端页面,老老实实的用原生框架如 Vue/React/Bootstrap 甚至 Blade 才是更好的选择。
Laravel 还有很优秀的设计我没有在这篇文章中指出来,如果你对 Laravel 感兴趣或者想写出一手还不错的代码,我真的建议你看一看 Laravel 的源码,看一看他的设计,我觉得这些设计在所有的语言中都是通用的,enjoy。
参考
以上就是为什么 Laravel 这么优秀的详细内容,更多请关注全栈开发网其它相关文章!本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 service@p2hp.com 进行投诉反馈,一经查实,立即处理!
上一篇:我们都应该学习PHP
相关内容









最新文章