
超越DeepSeek R1与GPT 4.5,百度周末两连发!文心大模型4.5及X1,免费!
3月16日,文心大模型4.5和文心大模型X1正式发布!
目前,两款模型已在文心一言官网上线,免费向用户开放。(https://yiyan.baidu.com)
同时,文心大模型4.5已上线百度智能云千帆大模型平台,企业用户和开发者登录即可调用API;文心大模型X1也即将在千帆上线。百度搜索、文小言APP等产品,将陆续接入文心大模型4.5和文心大模型X1,为用户带来更多元的体验。
文心大模型4.5
原生多模态基础大模型
文心大模型4.5是百度自主研发的新一代原生多模态基础大模型,通过多个模态联合建模实现协同优化,多模态理解能力优秀;具备更精进的语言能力,理解、生成、逻辑、记忆能力全面提升,去幻觉、逻辑推理、代码能力显著提升。
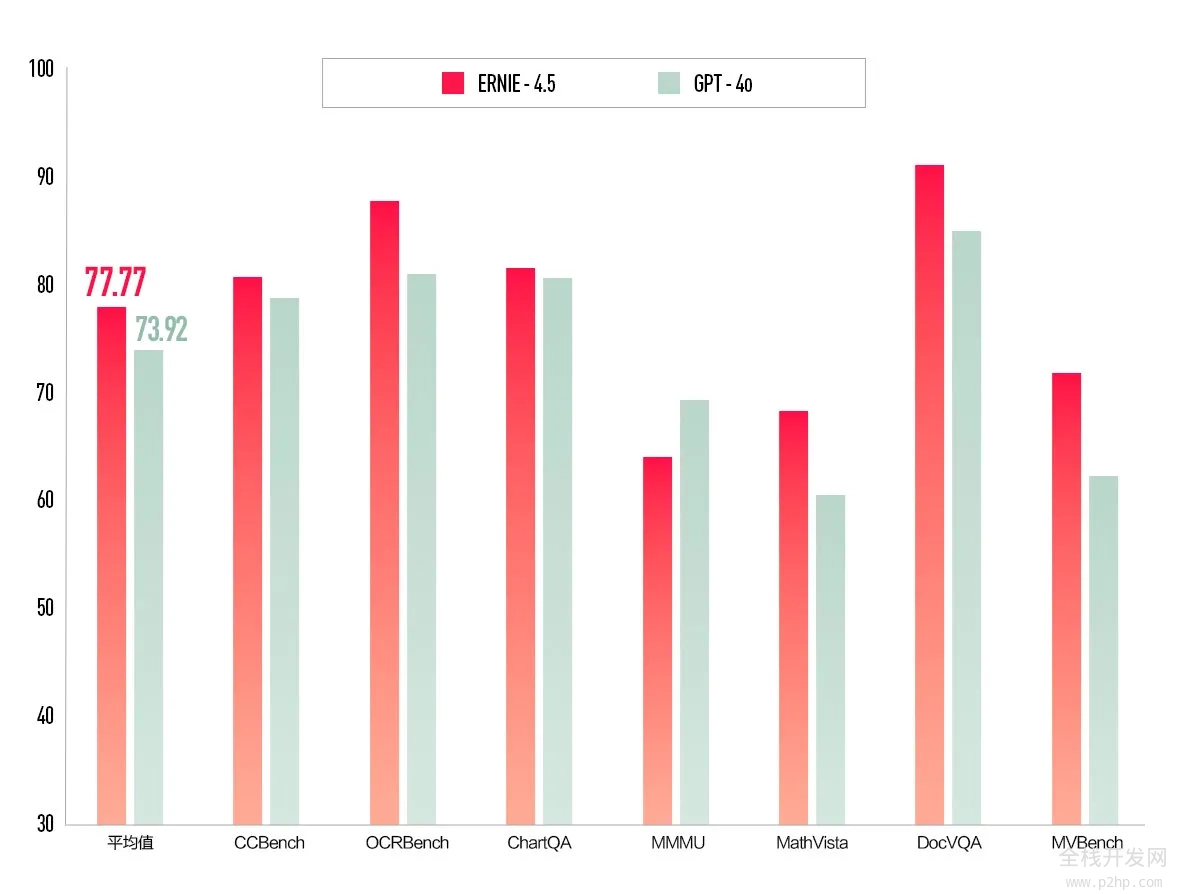

文心大模型4.5具备优秀的多模态理解能力,能对文字、图片、音频、视频等内容进行综合理解。例如,针对下面这道题,文心大模型4.5综合理解了图中的文字与图表内容,提取出题目考查的重点;并给出详细的解题步骤和细化的选项分析,最终得出正确答案。
不仅是“高智商”,文心大模型4.5也拥有“高情商”,网络梗图、讽刺漫画等等,理解起来都不在话下。例如,在下文中,这张梗图蕴含着“连续不一定可倒(导)、可倒(导)一定连续”的数学概念,文心大模型4.5不仅秒懂,点出梗图的巧妙和幽默;还能详细对其中蕴含的数学概念和画面逻辑进行解释。
文心大模型4.5能力显著增强,离不开这些关键技术:
◎ FlashMask动态注意力掩码:加速大模型灵活注意力掩码计算,有效提升长序列建模能力和训练效率,优化长文处理能力和多轮交互表现;
◎ 多模态异构专家扩展技术:根据模态特点构建模态异构专家,结合自适应模态感知损失函数,解决不同模态梯度不均衡问题,提升多模态融合能力;
◎ 时空维度表征压缩技术:在时空维度对图片和视频的语义表征进行高效压缩,大幅提升多模态数据训练效率,增强了从长视频中吸取世界知识的能力;
◎ 基于知识点的大规模数据构建技术:基于知识分级采样、数据压缩与融合、稀缺知识点定向合成技术,构建高知识密度预训练数据,提升模型学习效率,大幅降低模型幻觉;
◎ 基于自反馈的Post-training技术:融合多种评价方式的自反馈迭代式后训练技术,全面提升强化学习稳定性和鲁棒性,大幅提升预训练模型对齐人类意图能力。
文心大模型X1
能力更全面的深度思考模型
文心大模型X1具备更强的理解、规划、反思、进化能力,并支持多模态,是首个自主运用工具的深度思考模型。作为能力更全面的深度思考模型,文心大模型X1兼备准确、创意和文采,在中文知识问答、文学创作、文稿写作、日常对话、逻辑推理、复杂计算及工具调用等方面表现尤为出色。
作为能自主运用工具的大模型,文心大模型X1已支持高级搜索、文档问答、图片理解、AI绘图、代码解释器、网页链接读取、TreeMind树图、百度学术检索、商业信息查询、加盟信息查询等多款工具。
例如,让文心大模型X1使用中国各朝代历史人物典故,替换《寒窑赋》原文中的事例,它展现出清晰的思维链:找到和原文相似的人物典故→注意文风和句式→检查人物典故的适配度→行文保持结构流畅,最后生成了和原文立意、文风句式都基本一致的文本。
文心大模型X1能力的全面提升,得益于这些关键技术的支撑:
◎递进式强化学习训练方法:创新性地应用递进式强化学习方法,在创作、搜索、工具调用、推理等场景全面提升模型的综合应用能力;
◎基于思维链和行动链的端到端训练:针对深度搜索、工具调用等场景,根据结果反馈进行端到端的模型训练,显著提升训练效果;
◎ 多元统一的奖励系统:建立了统一的奖励系统,融合多种类型的奖励机制,为模型训练提供更加鲁棒的反馈。
体验全新文心大模型4.5与文心大模型X1
↓指路↓
文心一言官网,即刻免费体验两款全新大模型!(https://yiyan.baidu.com)
在百度智能云千帆大模型平台,现可直接调用文心大模型4.5API,输入价格低至0.004元/千tokens,输出价格低至0.016元/千tokens;文心大模型X1也即将在千帆平台上线,输入价格低至0.002元/千tokens,输出价格低至0.008元/千tokens。

2025是大模型技术全面迭代的一年,我们将在人工智能、数据中心、云基础设施上更大胆地投入,打造更好、更智能的下一代模型。
以上就是超越DeepSeek R1与GPT 4.5,百度周末两连发!文心大模型4.5及X1,免费!的详细内容,更多请关注全栈开发网其它相关文章!相关内容


















最新文章




