
混元-T1: 强化学习驱动,业内首个超大规模混合Mamba推理模型正式发布
简介
强化学习在大语言模型的后训练阶段开创了新的Scaling范式,这一突破正日益受到业界重视。随着OpenAI O系列模型与DeepSeek R1的相继发布,模型展现的卓越性能充分证明了强化学习在优化过程中的关键作用。
今年2月中,混元团队在腾讯元宝APP上线了基于混元中等规模底座的混元T1-Preview(Hunyuan-Thinker-1-Preview)推理模型,为用户带来了极致、快速的深度思考体验。
今天,我们非常高兴地向大家宣布混元大模型系列的深度思考模型已成功升级为混元-T1正式版,该模型基于我们在3月初发布的业界首个超大规模Hybrid-Transformer-Mamba MoE大模型TurboS快思考基座,通过大规模后训练显著扩展了推理能力,并进一步对齐人类偏好。
混元-T1相比前代T1-preview模型综合效果提升显著,是一款业界领先的前沿强推理大模型。
基于TurboS的T1在深度推理方向展现了独特的优势。TurboS的长文捕捉能力帮助Turbo-S有效解决了长文推理中经常遇到的上下文丢失和长距离信息依赖难题。其次,其Mamba架构专门优化了长序列的处理能力,通过高效的计算方式,能够在保证长文本信息捕捉能力的同时,显著降低计算资源的消耗,相同部署条件下、解码速度快2倍。
在模型后训练阶段,我们96.7%的算力投入到了强化学习训练,重点围绕纯推理能力的提升以及对齐人类偏好的优化。
我们收集了世界理科难题,涵盖数学/逻辑推理/科学/代码等,这些数据集涵盖了从基础的数学推理到复杂的科学问题解决,结合ground- truth的真实反馈,确保模型在面对各种推理任务时能够展现出卓越的能力。
在训练方案上,我们采用了课程学习的方式逐步提升数据难度,同时阶梯式扩展模型上下文长度,使得模型推理能力提升的同时学会高效利用token进行推理。
在训练策略上,我们参考了经典强化学习的数据回放/阶段性策略重置等策略,显著提升了模型训练长期稳定性50%以上。在对齐人类偏好阶段,我们采用了self-rewarding(基于T1- preview 的早期版本对模型输出进行综合评价、打分) + reward mode 的统一奖励系统反馈方案,指导模型进行自我提升,模型在答复中展现了更丰富的内容细节以及更高效的信息。
混元-T1除了在各类公开benchmark、如MMLU-pro、CEval、AIME、Zebra Loigc等中英文知识和竞赛级数学、逻辑推理指标上基本持平或略超R1外,在内部人工体验集评估上也能对标,其中文创指令遵循、文本摘要、agent能力方面略有胜。
从综合评测指标来看,混元T1的整体效果能对标一线前沿的推理模型。综合能力评测方面,在MMLU- PRO上T1仅次于O1,高达87.2分,这个测试集涵盖人文社科、理工科等14个领域的题目,主要测试模型对广泛知识的记忆和理解,另外还有聚焦于专业领域知识和复杂科学推理的GPQA- diamond,主要包括博士级别的物理/化学/生物难题,T1达到了69.3分。
理科方面,我们测试了代码/数学/逻辑推理等注重强推理能力的场景,在LiveCodeBench的代码评测中,T1达到了64.9分。同时,T1在数学方面也表现卓越,尤其是在MATH-500上,取得了96.2分的好成绩,紧跟DeepSeek R1,显示出T1在解决数学题方面的综合能力。除此之外,T1还在多项对齐任务、指令跟随任务和工具利用任务中展现出了非常强的适应性。例如,在ArenaHard任务中,T1拿下了91.9分的成绩。
模型效果
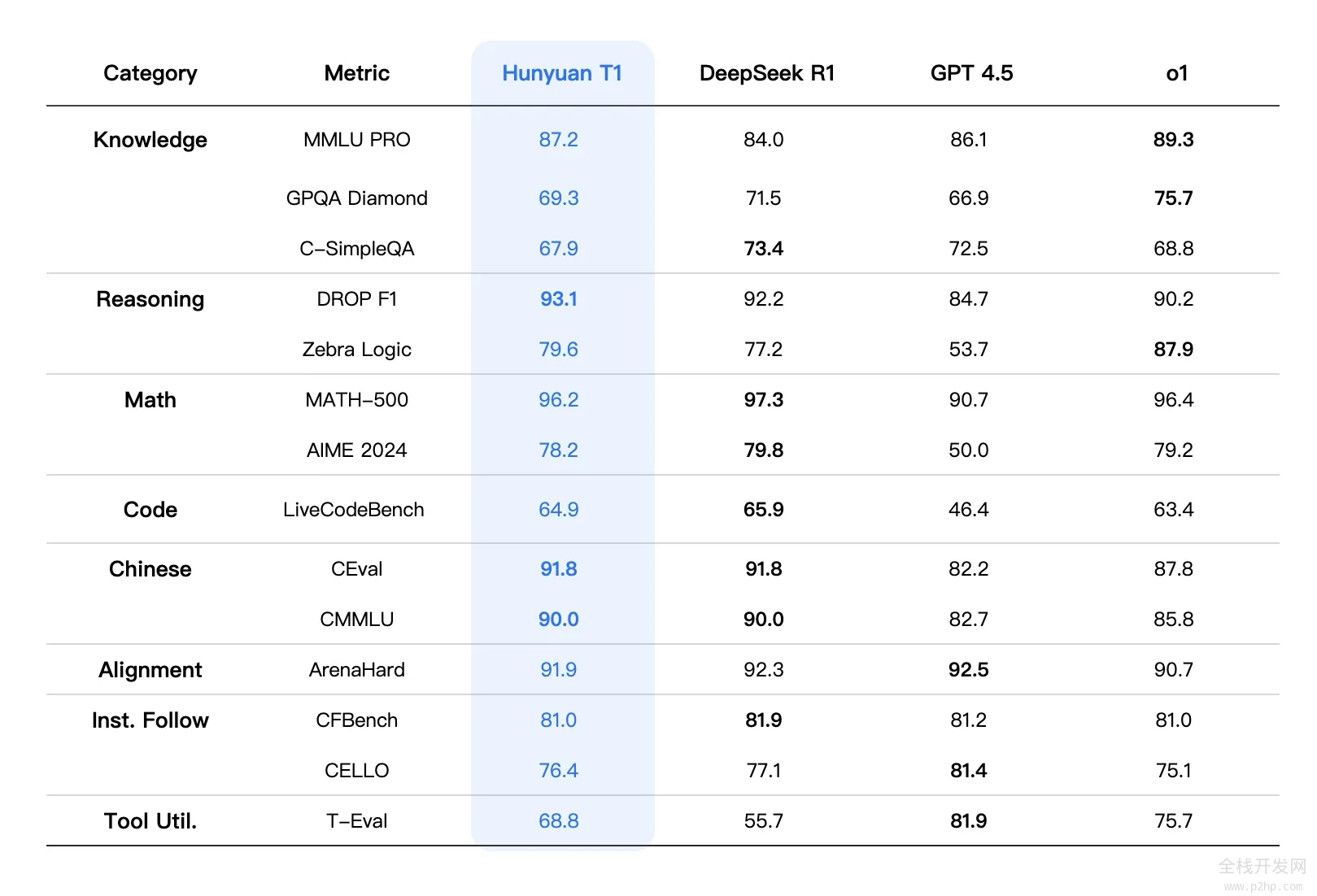
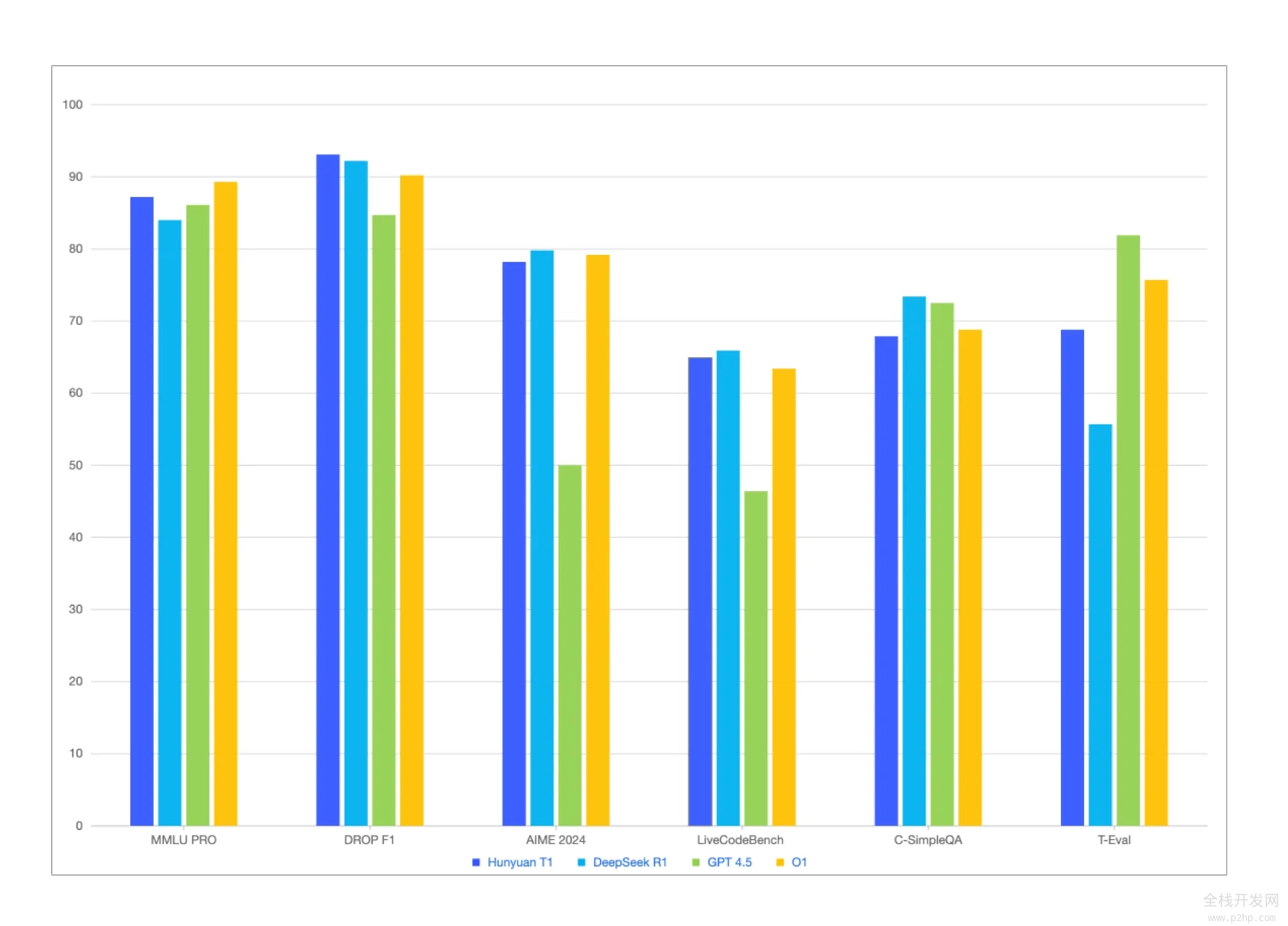
注:表格中,其它模型的评测指标来自官方评测结果,官方评测结果中没有的部分来自混元内部评测平台结果
相关内容














最新文章









