
一文图解 DeepSeek-R1 的出众推理能力从何而来?
编者按: DeepSeek-R1 到底有什么特别之处?它为什么能在推理任务上取得如此出色的表现?这背后的训练方法又蕴含着怎样的创新?
当我们需要模型处理数学题、编程任务,或是进行逻辑分析时,高质量的推理能力显得尤为重要。然而,传统的训练方法往往需要耗费大量人力物力,这对许多研究团队和企业来说都是不小的负担。
今天这篇深度解析 DeepSeek-R1 训练方法的文章,将展示一个令人耳目一新的解决方案:如何通过创新的强化学习方法,在少量高质量人工标注数据的情况下,打造出一个推理能力出众的 AI 模型。文章详细介绍了 DeepSeek 团队如何通过 "自动验证机制" 来训练模型,这种方法不仅大大降低了对人工标注数据的依赖,还能持续提升模型的推理质量。
作者 | Jay Alammar
编译 | 岳扬
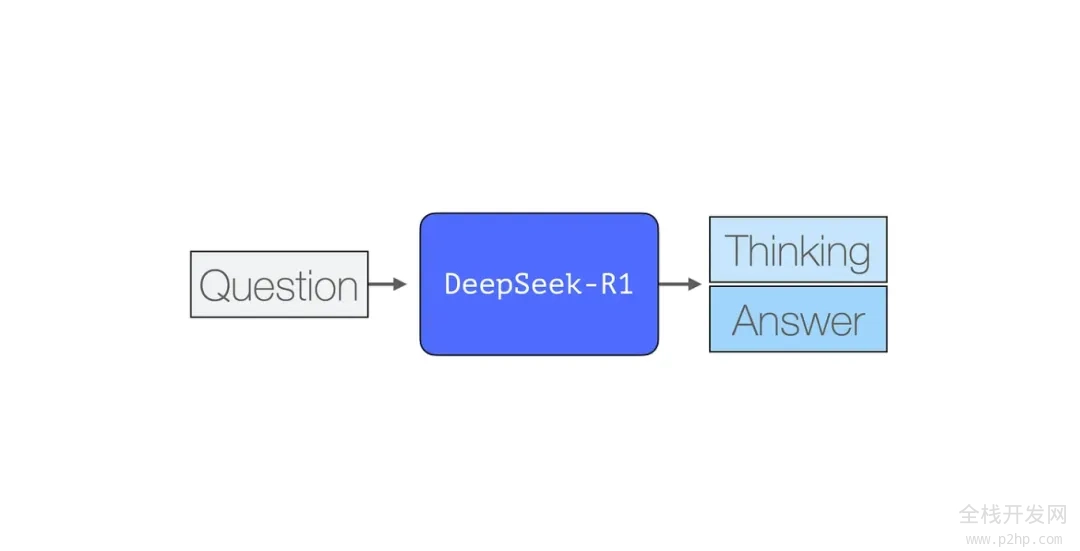
DeepSeek-R1 代表了人工智能发展的又一重要里程碑。对于机器学习领域的研究人员与开发者群体而言,这次发布之所以备受关注,主要有以下两点:
- 首先,这是一款开源权重的模型,并且提供了更小的、经过蒸馏的版本;
- 其次,它公布并深入探讨了训练方法,该方法能够复现类似于 OpenAI O1 的推理模型。
本文将带您了解这一模型的构建过程。
目录
01 回顾:大语言模型(LLMs)的训练方法
02 DeepSeek-R1 的训练步骤
2.1- 长推理链的 SFT 数据
2.2- 一个过渡性的、擅长推理的高质量大语言模型(但在非推理任务上表现稍逊)
2.3- 利用大规模强化学习(RL)构建推理模型
2.3.1- 以推理为导向的大规模强化学习(R1-Zero)
2.3.2- 利用过渡性推理模型生成 SFT 推理数据
2.3.3- 常规强化学习训练阶段
03 模型架构
01 回顾:大语言模型(LLMs)的训练方法
与大多数现有的大语言模型一样,DeepSeek-R1 也是逐个生成 token,但其独特之处在于擅长解决数学和推理问题。这是因为它能够通过生成一系列思考 tokens 来详细阐述其思考过程,从而更加深入地处理问题。

下图摘自书籍《Hands-On Large Language Models》的第 12 章,展示了创建高质量大语言模型的三个主要步骤:
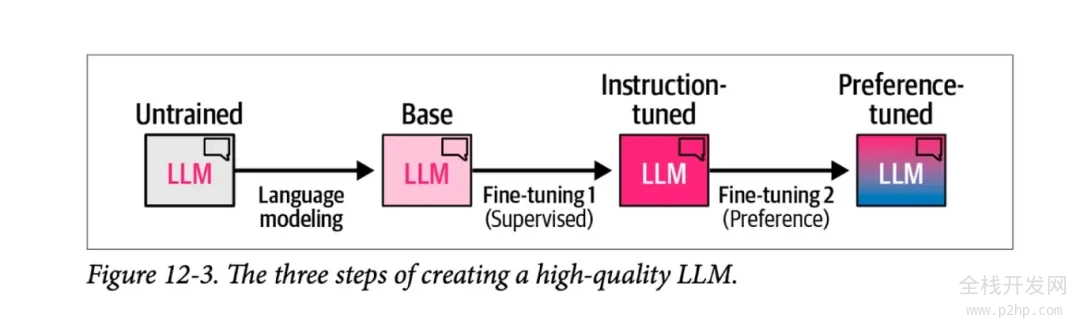
1)语言建模阶段,我们利用海量的网络数据训练模型预测下一个词汇,从而得到一个基础模型。
2)监督式微调阶段,这一步骤让模型在执行指令和回答问题时更加得心应手,进而得到一个指令调优的模型或称为监督式微调 / SFT 模型。
3)最后是偏好调优阶段,这一步骤进一步优化模型的行为,使其更符合人类偏好,最终形成的是你在各种平台和应用中使用的偏好调优后的 LLM。
02 DeepSeek-R1 的训练步骤
DeepSeek-R1 遵循了这一通用框架。其第一步的具体内容源自于之前关于 DeepSeek-V3 模型的研究论文 [1]。R1 使用的是该论文中的基础模型(并非最终的 DeepSeek-V3 模型),并且同样经历了 SFT(监督式微调)和偏好调优阶段,但它的独特之处在于这些阶段的具体操作方法。
在 R1 的构建过程中,有三个关键点值得特别关注。
2.1 长推理链的 SFT 数据
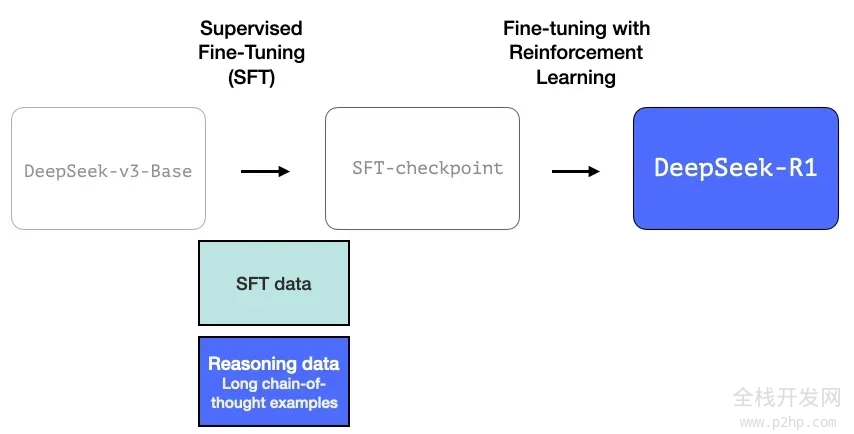
这些长思维链推理的实例数量庞大(总共达到 60 万个)。如此大规模的实例获取难度极高,且若要依靠人工标注,成本也将极为昂贵。 因此,这些实例的创建过程是我们需要强调的第二个独特之处。
2.2 一个过渡性的、擅长推理的高质量 LLM(但在非推理任务上表现稍逊)
这些数据是由 R1 的前身,一个专注于推理但尚未命名的姊妹模型所生成的。这个姊妹模型受到了另一个模型 R1-Zero 的启发(我们将在稍后讨论)。它之所以意义重大,并不是因为它是一个非常好用的 LLM,而在于在它的创建过程中,几乎无需依赖标注数据,仅通过大规模的强化学习,就能培育出一个擅长处理推理问题的模型。
接着,这个未命名的推理专家模型的输出结果,可以用来训练一个更为多能的模型,它不仅能够处理推理任务,还能应对其他类型的任务,满足用户对大语言模型(LLM)的普遍期待。
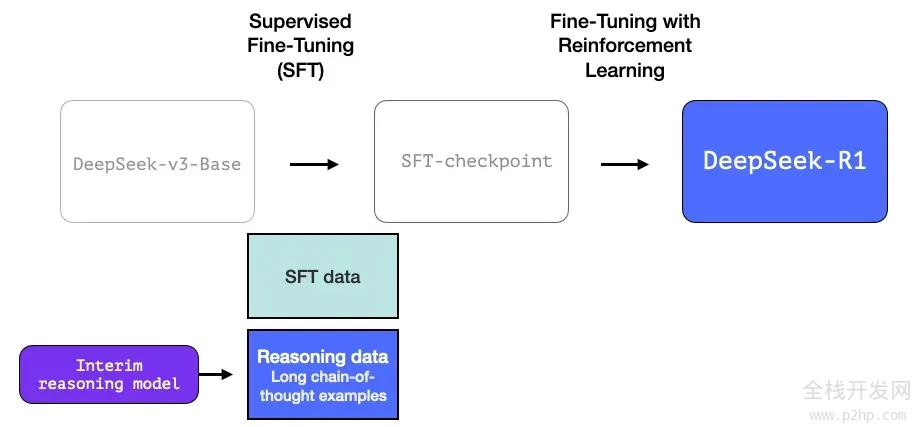
2.3 利用大规模强化学习(RL)构建推理模型
此处分为两个步骤:
2.3.1- 以推理为导向的大规模强化学习(R1-Zero)
在此过程中,我们利用强化学习(RL)来构建一个临时的推理模型。随后,这个模型被用于生成用于监督式微调(SFT)的推理示例。然而,能够创建这个模型的关键,在于之前的一项实验,该实验成功打造了一个名为 DeepSeek-R1-Zero 的早期模型。
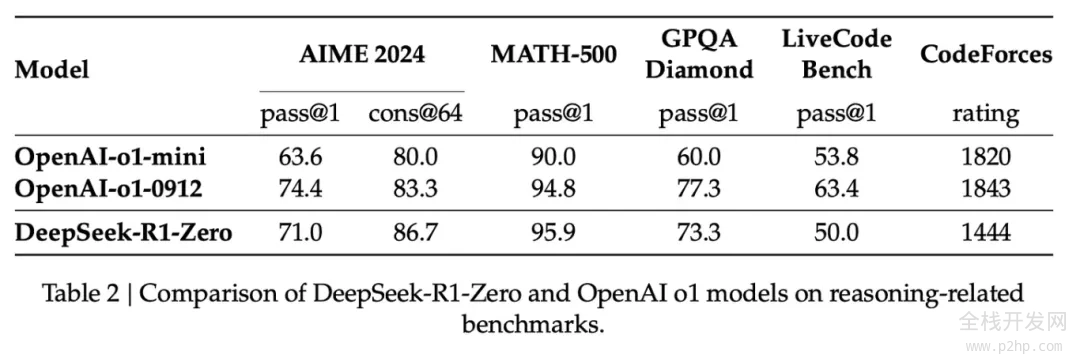
R1-Zero 的独特之处在于,它能够在没有经过标注的 SFT 训练集的情况下,依然在推理任务上表现卓越。它的训练过程直接从预训练的基础模型出发,通过强化学习训练(跳过了 SFT 阶段)。它的表现非常出色,能够与 O1 模型相媲美。
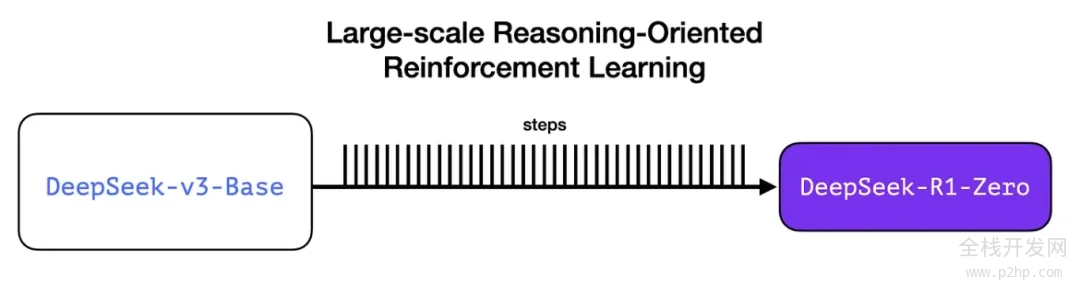
这一成就重要重大,因为数据一直是机器学习模型能力的助推器。那么,这个模型是如何打破这一传统的呢?这主要归功于以下两点:
1- 现代基础模型在质量和能力上已经达到了一个临界点(这个基础模型是在高达 14.8 万亿的高质量 tokens 上训练而成的)。
2- 与通用聊天或写作请求不同,推理问题可以实现自动验证或标注。 可以通过以下这个示例来说明这一点。
示例:推理问题的自动验证
以下是一个可能出现在 RL 训练步骤中的提示词 / 问题:
编写一段 Python 代码,获取一个数字列表,返回排序后的列表,并在列表开头添加数字 42。
这样的问题非常适合自动验证。假设我们将这个问题抛给正在训练的模型,它会生成:
- 使用软件语法检查器可以验证生成的代码是否为有效的 Python 代码。
- 我们可以运行这段 Python 代码,以检查其是否能够成功执行。
- 其他现代代码生成 LLM 可以创建单元测试来验证代码的行为是否符合预期(它们自身无需具备推理能力)。
- 我们甚至可以进一步,通过测量代码的执行时间,让训练过程偏好那些性能更优的解决方案,即使其他解决方案也是正确的 Python 程序。
在训练步骤中,我们可以向模型提出这样的问题,并生成多种可能的解决方案。
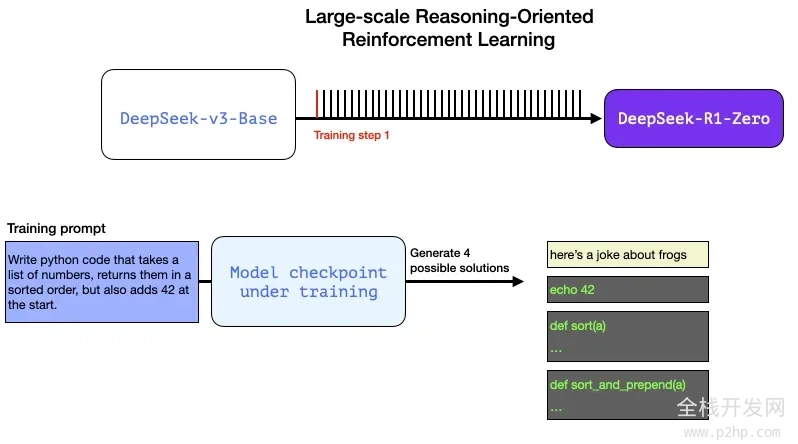
我们可以不依赖人工干预,自动进行检查,发现第一个输出根本不是代码。第二个输出是代码,但并非 Python 代码。第三个输出看似是一个解决方案,却未能通过单元测试,而第四个输出则是正确的解决方案。
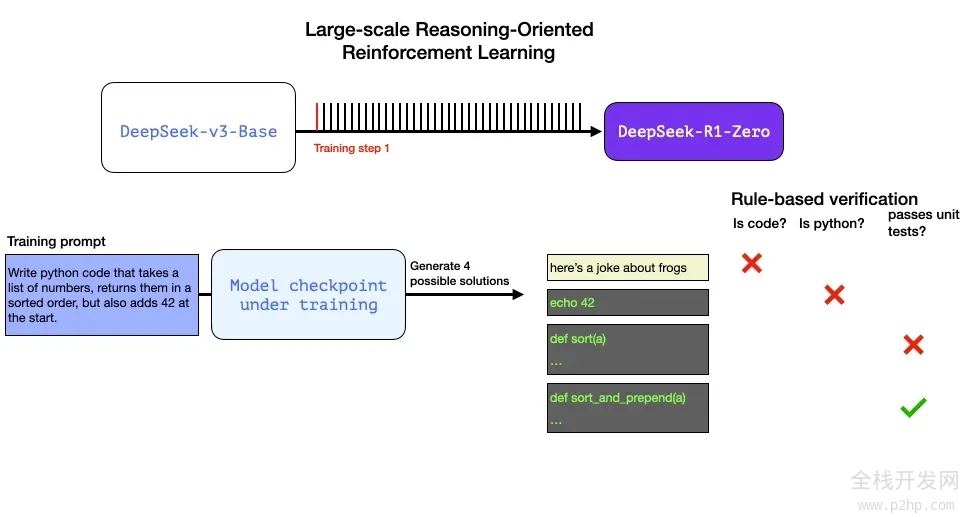
这些反馈都是可以直接用来优化模型的信号。这一过程当然是在大量示例(以小批量形式)和连续的训练步骤中完成的。

这些奖励信号和模型更新是模型在强化学习训练过程中不断进步的关键,如下图所示。
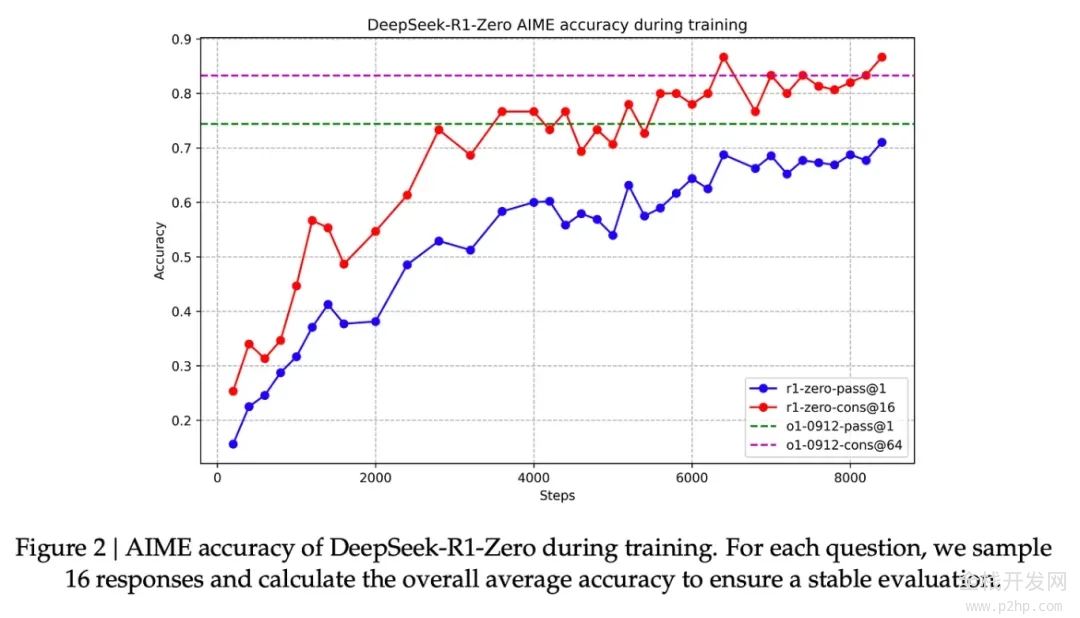
与此能力提升相伴的是,模型生成了更长的响应,即使用了更多的思考 tokens 来处理问题。
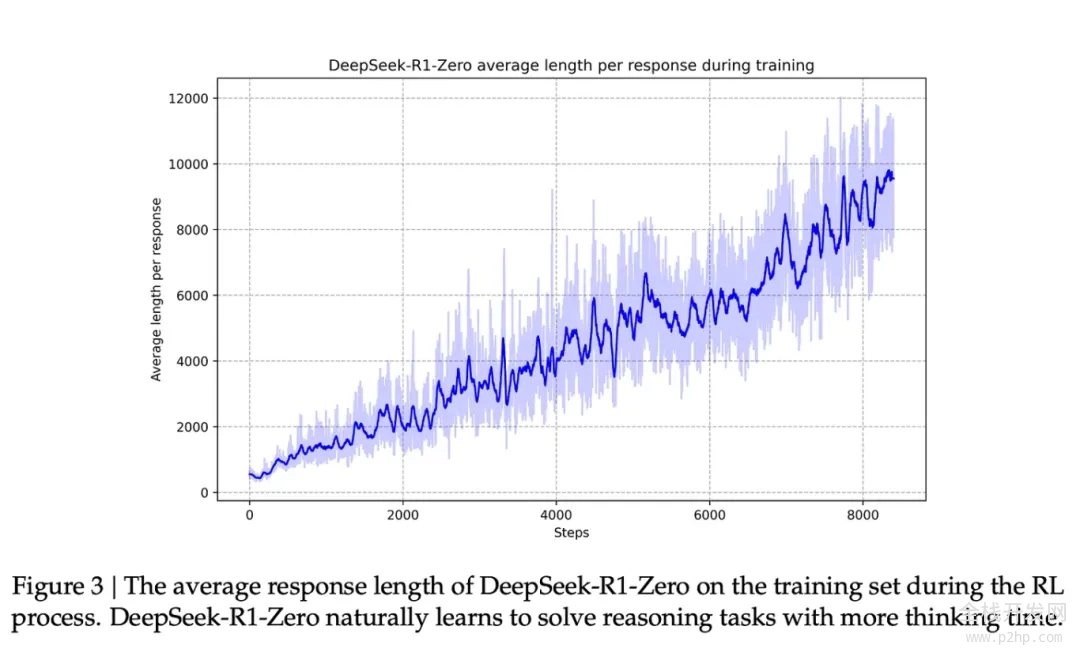
尽管这个过程很有价值,但 R1-Zero 模型在推理问题上的高分表现背后,仍存在一些问题,使其实际可用性未达理想状态。
虽然 DeepSeek-R1-Zero 展现出了卓越的推理能力,并自主发展出了出人意料的强大推理行为,但它也遭遇了一些挑战,比如文本可读性不佳和语言混杂等问题。
R1 模型的设计目标是提高可用性。因此,它(DeepSeek-R1-Zero)不仅仅完全依赖于强化学习过程,而是如前文所述,在以下两个方面发挥作用:
1- 创建一个过渡性的推理模型,用以生成监督式微调(SFT)的数据点。
2- 训练 R1 模型,以在推理和非推理问题上取得进步(利用其他类型的验证器)。
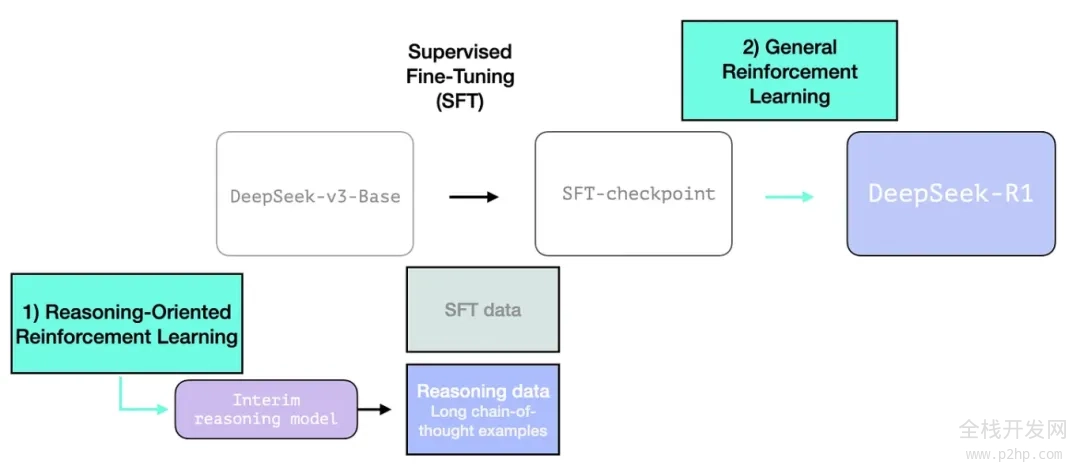
2.3.2- 利用过渡性推理模型生成 SFT 推理数据
为了提升过渡性推理模型的实际效用,我们对其进行了监督式微调(SFT)训练,这一步骤在数千个推理问题示例上进行(部分示例由 R1-Zero 生成并筛选)。在论文中,这些示例被称为 "冷启动数据"。
2.3.1. 冷启动阶段
与 DeepSeek-R1-Zero 不同,为了防止基础模型在强化学习训练初期出现不稳定的冷启动问题,对于 DeepSeek-R1,我们构建并收集了少量长思维链(CoT)数据对模型进行微调,将其作为初始的强化学习策略模型。为收集这类数据,我们探索了多种方法:使用带有长 CoT 示例的小样本提示技术、直接提示模型生成带有反思和验证的详细答案、收集 DeepSeek-R1-Zero 生成的易读格式输出,并通过人工标注员对结果进行后处理细化。
但或许你会问,既然我们已经有了这些数据,为什么还需要依赖强化学习过程呢?答案在于数据的规模。我们可以获取的可能只有 5,000 个示例的数据集,而训练 R1 则需要 600,000 个示例。 这个过渡性模型帮助我们缩小了这一差距,并使我们能够合成生成那些极为重要的数据。
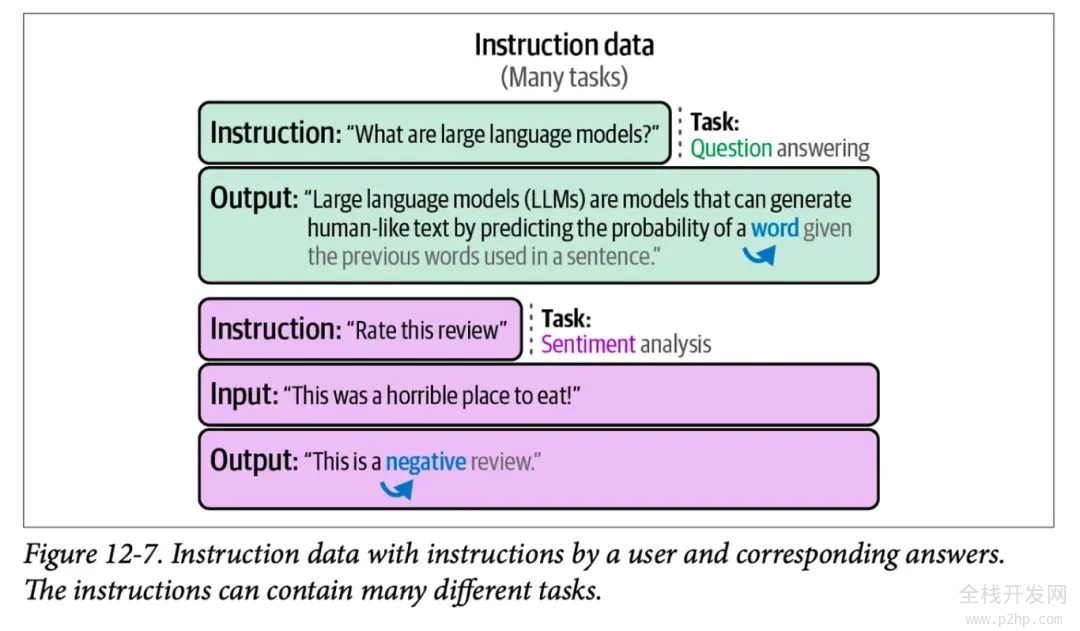
对于监督式微调(SFT)这一概念,可能你还不太熟悉,它是一种训练过程,通过向模型展示形式为提示词和正确补全的训练示例来进行。下面这个图展示了书籍《Hands-On Large Language Models》第 12 章中的一些 SFT 训练示例:
2.3.3- 常规强化学习训练阶段
这样,R1 模型不仅在推理任务上表现卓越,还能有效地应对其他非推理类任务。这一过程与我们之前提到的强化学习过程相似,但因为它涵盖了非推理领域的应用,所以它还引入了一个实用性奖励模型和安全性奖励模型(与 Llama 模型有相似之处),用于处理这些应用领域的提示词。
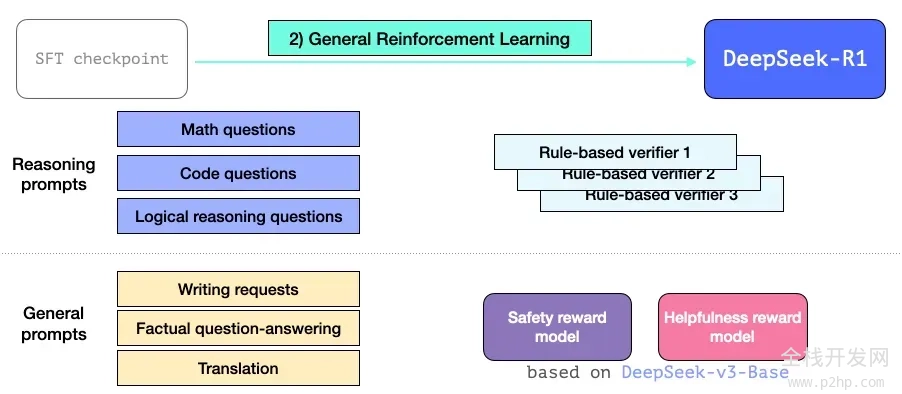
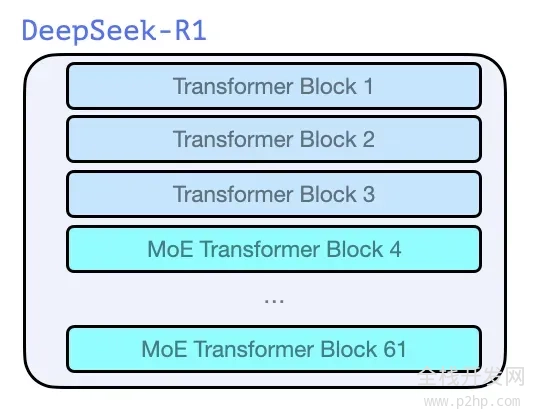
03 模型架构
与 GPT2 [2] 和 GPT3 [3] 等同源的早期模型一样,DeepSeek-R1 也是由 Transformer [4] 解码器块堆叠而成,总共包含了 61 个这样的块。其中,前三个块是密集层,而后续的则是采用了混合专家层(MoE)。
关于模型的维度大小和其他超参数配置,具体信息如下:
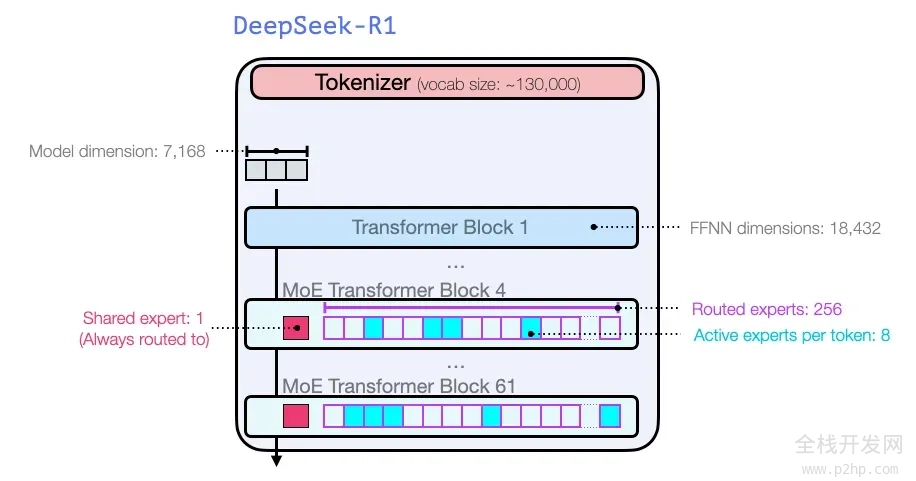
有关模型架构的更多详细信息,可以在他们之前发表的两篇论文中找到:
- DeepSeek-V3 Technical Report[1]
- DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models[5]
04 Conclusion
通过上述内容,相信你现在应该对 DeepSeek-R1 模型有了基本的理解。
如果你觉得需要更多基础知识来理解这篇文章,我建议你获取一本《Hands-On Large Language Models》[6] 或者在线在 O'Reilly [7] 上阅读,并在 Github [8] 上查看相关内容。
Thanks for reading!
Hope you have enjoyed and learned new things from this blog!
About the author
Jay Alammar
Machine learning R&D. Builder. Writer. Visualizing artificial intelligence & machine learning one concept at a time. @CohereAI.
END
本期互动内容 🍻
❓你觉得 AI 模型最难掌握的是哪种推理能力?欢迎在评论区分享你的观点👇
🔗文中链接🔗
[1]https://arxiv.org/pdf/2412.19437v1
[2]https://jalammar.github.io/illustrated-gpt2/
[3]https://jalammar.github.io/how-gpt3-works-visualizations-animations/
[4]https://jalammar.github.io/illustrated-transformer/
[5]https://arxiv.org/pdf/2401.06066
[7]https://learning.oreilly.com/library/view/hands-on-large-language/9781098150952/
[8]https://github.com/handsOnLLM/Hands-On-Large-Language-Models
原文链接:
https://newsletter.languagemodels.co/p/the-illustrated-deepseek-r1
以上就是一文图解 DeepSeek-R1 的出众推理能力从何而来?的详细内容,更多请关注全栈开发网其它相关文章!
上一篇:OpenAI发布最新模型规范
相关内容


















最新文章






