
一文读懂:DeepSeek新模型大揭秘,为何它能震动全球AI圈
【编者按】课代表系列-AI大事儿的最快、最全解读,本文关注DeepSeek-R1在技术上最重要的突破——用纯深度学习的方法让AI自发涌现出推理能力。这一研究可能会对模型推理训练后续的范式产生深刻影响。
时隔不到一个月,DeepSeek又一次震动全球AI圈。
去年 12 月,DeepSeek推出的DeepSeek-V3在全球AI领域掀起了巨大的波澜,它以极低的训练成本,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。
腾讯科技曾对此模型进行深度解读,用最简单直白的语言阐释其实现低成本和高效能的技术背景。
和上次不同的是,这次推出的新模型DeepSeek-R1不仅成本低,更是在技术上有了大幅提升。
而且,它还是一个开源模型。
这款新模型延续了其高性价比的优势,仅用十分之一的成本就达到了GPT-o1级别的表现。
所以,很多业内人士甚至喊出了“DeepSeek接班OpenAI”的口号。
比如,前Meta AI工作人员、知名AI论文推特作者Elvis就强调,DeepSeek-R1的论文堪称瑰宝,因为它探索了提升大语言模型推理能力的多种方法,并发现了其中更明确的涌现特性。

另一位AI圈大V Yuchen Jin则认为,DeepSeek-R1论文中提出的,模型利用纯RL方法引导其自主学习和反思推理这一发现,意义非常重大。
英伟达GEAR Lab项目负责人Jim Fan在推特中也提到了,DeepSeek-R1用通过硬编码规则计算出的真实奖励,而避免使用任何 RL 容易破解的学习奖励模型。这使得模型产生了自我反思与探索行为的涌现。
Jim Fan 甚至认为,它们做了OpenAI本来应该做的事,开源。

那么问题来了,他们所提到的纯RL方法训练模型是指什么?
模型出现的“Aha Moment”,又凭什么能证明AI具有了涌现能力?
我们更想知道的是,DeepSeek-R1的这一重要创新对于AI领域未来的发展,究竟意味着什么?
用最简单的配方,回归最纯粹的强化学习
在o1推出之后,推理强化成了业界最关注的方法。
一般来说,一个模型在训练过程中只会尝试一种固定训练方法来提升推理能力。
而DeepSeek团队在R1的训练过程中,直接一次性实验了三种截然不同的技术路径:直接强化学习训练(R1-Zero)、多阶段渐进训练(R1)和模型蒸馏,还都成功了。多阶段渐进训练方法和模型蒸馏都包含着很多创新意义元素,对行业有着重要影响。
其中最让人激动的,还是直接强化学习这个路径。因为DeepSeek-R1是首个证明这一方法有效的模型。
我们先来了解一下,训练AI的推理能力传统的方法通常是什么:一般是通过在SFT(监督微调)加入大量的思维链(COT)范例,用例证和复杂的如过程奖励模型(PRM)之类的复杂神经网络奖励模型,来让模型学会用思维链思考。
甚至会加入蒙特卡洛树搜索(MCTS),让模型在多种可能中搜索最好的可能。
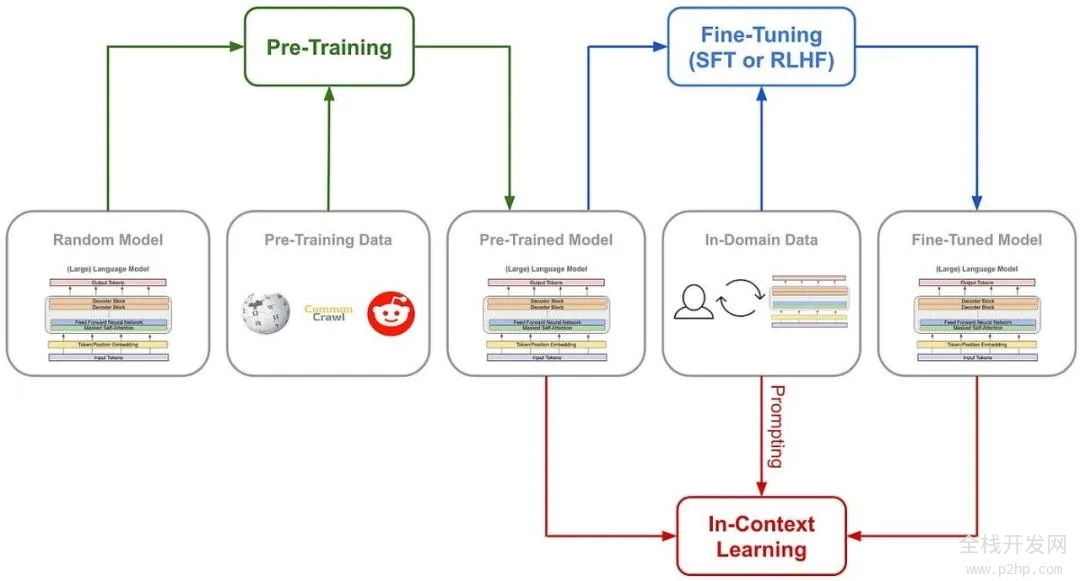
传统的模型训练路径
但DeepSeek-R1-Zero选择了一条前所未有的路径“纯”强化学习路径,它完全抛开了预设的思维链模板(Chain of Thought)和监督式微调(SFT),仅依靠简单的奖惩信号来优化模型行为。
这就像让一个天才儿童在没有任何范例和指导的情况下,纯粹通过不断尝试和获得反馈来学习解题。
DeepSeek-R1-Zero 有的只是一套最简单的奖励系统,来激发AI的推理能力。
这个规则就两条:
1. 准确性奖励:准确性奖励模型评估响应是否正确。对了就加分,错了扣分。评价方法也很简单:例如,在具有确定性结果的数学问题中,模型需要以指定格式(如
2. 格式奖励:格式奖励模型强制要求模型将其思考过程置于
为了准确观察模型在强化学习(RL)过程中的自然进展,DeepSeek甚至有意将系统提示词仅约束限制在这种结构格式上,来避免任何内容特定的偏见——例如强制让模型进行反思性推理或推广特定的问题解决策略。

R1 Zero的系统提示词
靠着这么一个简单的规则,让AI在GRPO(Group Relative Policy Optimization)的规则下自我采样+比较,自我提升。
GRPO的模式其实比较简单,通过组内样本的相对比较来计算策略梯度,有效降低了训练的不稳定性,同时提高了学习效率。
简单来说,你可以把它想象成老师出题,每道题让模型同时回答多次,然后用上面的奖惩规则给每个答案打分,根据追求高分、避免低分的逻辑更新模型。
这个流程大概是这样的:
输入问题 → 模型生成多个答案 → 规则系统评分 → GRPO计算相对优势 → 更新模型
这种直接训练方法带来了几个显著的优势。首先是训练效率的提升,整个过程可以在更短的时间内完成。其次是资源消耗的降低,由于省去了SFT和复杂的奖惩模型,计算资源的需求大幅减少。
更重要的是,这种方法真的让模型学会了思考,而且是以“顿悟”的方式学会的。
用自己的语言,在“顿悟”中学习
我们是怎么看出模型在这种非常“原始”的方法下,是真的学会了“思考”的呢?
论文记录了一个引人注目的案例:在处理一个涉及复杂数学表达式 √a - √(a + x) = x 的问题时,模型突然停下来说"Wait, wait. Wait. That's an aha moment I can flag here"(等等、等等、这是个值得标记的啊哈时刻),随后重新审视了整个解题过程。这种类似人类顿悟的行为完全是自发产生的,而不是预先设定的。

这种顿悟往往是模型思维能力跃升的时刻。
因为根据DeepSeek的研究,模型的进步并非均匀渐进的。在强化学习过程中,响应长度会出现突然的显著增长,这些"跳跃点"往往伴随着解题策略的质变。这种模式酷似人类在长期思考后的突然顿悟,暗示着某种深层的认知突破。

在这种伴随着顿悟的能力提升下,R1-Zero在数学界享有盛誉的AIME竞赛中从最初的15.6%正确率一路攀升至71.0%的准确率。而让模型对同一问题进行多次尝试时,准确率甚至达到了86.7%。这不是简单的看过了就会做了——因为AIME的题目需要深度的数学直觉和创造性思维,而不是机械性的公式应用。模型基本必须能推理,才可能有这样的提升。
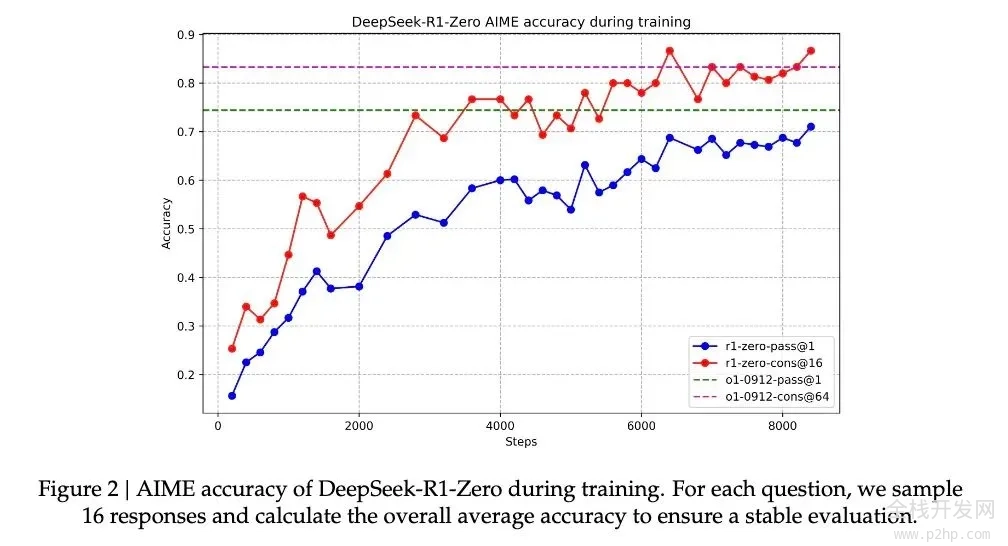
另一个模型确实通过这种方法学会了推理的另一个核心证据,是模型响应长度会根据问题的复杂度自然调节。这种自适应行为表明,它不是在简单地套用模板,而是真正理解了问题的难度,并相应地投入更多的"思考时间"。就像人类面对简单的加法和复杂的积分会自然调整思考时间一样,R1-Zero展现出了类似的智慧。
最有说服力的或许是模型展现出的迁移学习能力。在完全不同的编程竞赛平台Codeforces上,R1-Zero达到了超过96.3%人类选手的水平。这种跨域表现表明,模型不是在死记硬背特定领域的解题技巧,而是掌握了某种普适的推理能力。
一个聪明,但口齿不清的天才
尽管R1-Zero展现出了惊人的推理能力,但研究者们很快发现了一个严重的问题:它的思维过程往往难以被人类理解。
论文坦诚地指出,这个纯强化学习训练出来的模型存在"poor readability"(可读性差)和"language mixing"(语言混杂)的问题。
这个现象其实很好理解:R1-Zero完全通过奖惩信号来优化其行为,没有任何人类示范的"标准答案"作为参考。就像一个天才儿童自创了一套解题方法,虽然屡试不爽,但向别人解释时却语无伦次。它在解题过程中可能同时使用多种语言,或者发展出了某种特殊的表达方式,这些都让其推理过程难以被追踪和理解。
正是为了解决这个问题,研究团队开发了改进版本DeepSeek-R1。通过引入更传统的"cold-start data"(冷启动数据)和多阶段训练流程,R1不仅保持了强大的推理能力,还学会了用人类易懂的方式表达思维过程。这就像给那个天才儿童配了一个沟通教练,教会他如何清晰地表达自己的想法。
在这一调教下之后,DeepSeek-R1展现出了与OpenAI o1相当甚至在某些方面更优的性能。在MATH基准测试上,R1达到了77.5%的准确率,与o1的77.3%相近;在更具挑战性的AIME 2024上,R1的准确率达到71.3%,超过了o1的71.0%。在代码领域,R1在Codeforces评测中达到了2441分的水平,高于96.3%的人类参与者。
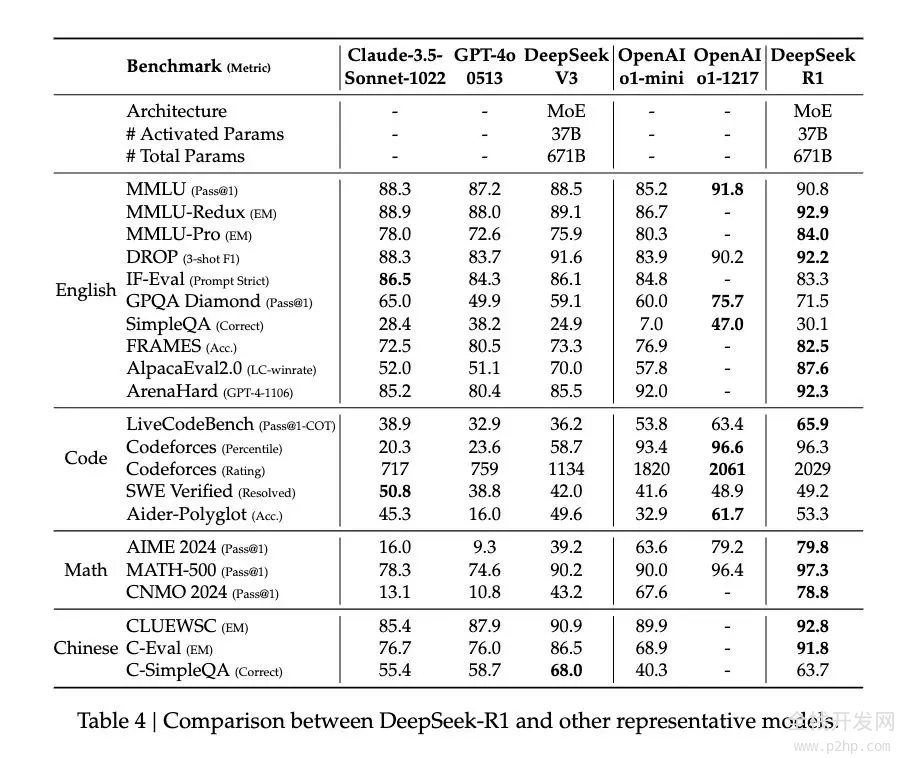
然而,DeepSeek-R1 Zero的潜力似乎更大。它在AIME 2024测试中使用多数投票机制时达到的86.7%准确率——这个成绩甚至超过了OpenAI的o1-0912。这种"多次尝试会变得更准确"的特征,暗示R1-Zero可能掌握了某种基础的推理框架,而不是简单地记忆解题模式。
论文数据显示,从MATH-500到AIME,再到GSM8K,模型表现出稳定的跨域性能,特别是在需要创造性思维的复杂问题上。这种广谱性能提示R1-Zero可能确实培养出了某种基础的推理能力,这与传统的特定任务优化模型形成鲜明对比。
所以,虽然口齿不清,但也许DeepSeek-R1-Zero才是真正理解了推理的“天才”。
纯粹强化学习,也许才是通向AGI的意外捷径
之所以DeepSeek-R1的发布让圈内人的焦点都投向了纯强化学习方法,因为它完全可以说得上是打开了AI 进化的一条新路径。
R1-Zero——这个完全通过强化学习训练出来的AI模型,展现出了令人惊讶的通用推理能力。它不仅在数学竞赛中取得了惊人成绩。
更重要的是,R1-Zero不仅是在模仿思考,而是真正发展出了某种形式的推理能力。
因为在过往的训练方法中,尤其在监督微调中使用训练好的神经网络来评估质量的话,模型可能学会触发奖励模型的特定模式,生成对奖励模型"口味"的内容,而不是真正提升推理能力。换句话说,AI系统找到了获得高奖励但实际上违背训练目标的投机取巧方式。这就是我们常说的奖励欺骗(reward hacking)。但R1-Zero用极简的奖励规则基本避免了奖励欺骗的可能性——规则太简单了,没有什么“口味”可以去模仿。模型在这个情况下发展出的推理能力更可信,也更自然。
这个发现可能会改变我们对机器学习的认识:传统的AI训练方法可能一直在重复一个根本性的错误,我们太专注于让AI模仿人类的思维方式了,业界需要重新思考监督学习在AI发展中的角色。通过纯粹的强化学习,AI系统似乎能够发展出更原生的问题解决能力,而不是被限制在预设的解决方案框架内。
虽然R1-Zero在输出可读性上存在明显缺陷,但这个"缺陷"本身可能恰恰印证了其思维方式的独特性。就像一个天才儿童发明了自己的解题方法,却难以用常规语言解释一样。这提示我们:真正的通用人工智能可能需要完全不同于人类的认知方式。
这才是真正的强化学习。就像著名教育家皮亚杰的理论:真正的理解来自于主动建构,而不是被动接受。
以上就是一文读懂:DeepSeek新模型大揭秘,为何它能震动全球AI圈的详细内容,更多请关注全栈开发网其它相关文章!本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 service@p2hp.com 进行投诉反馈,一经查实,立即处理!
相关内容


















最新文章







